|
Jason J. Corso
|
Snippet Topic: Activity Recognition
Action Bank 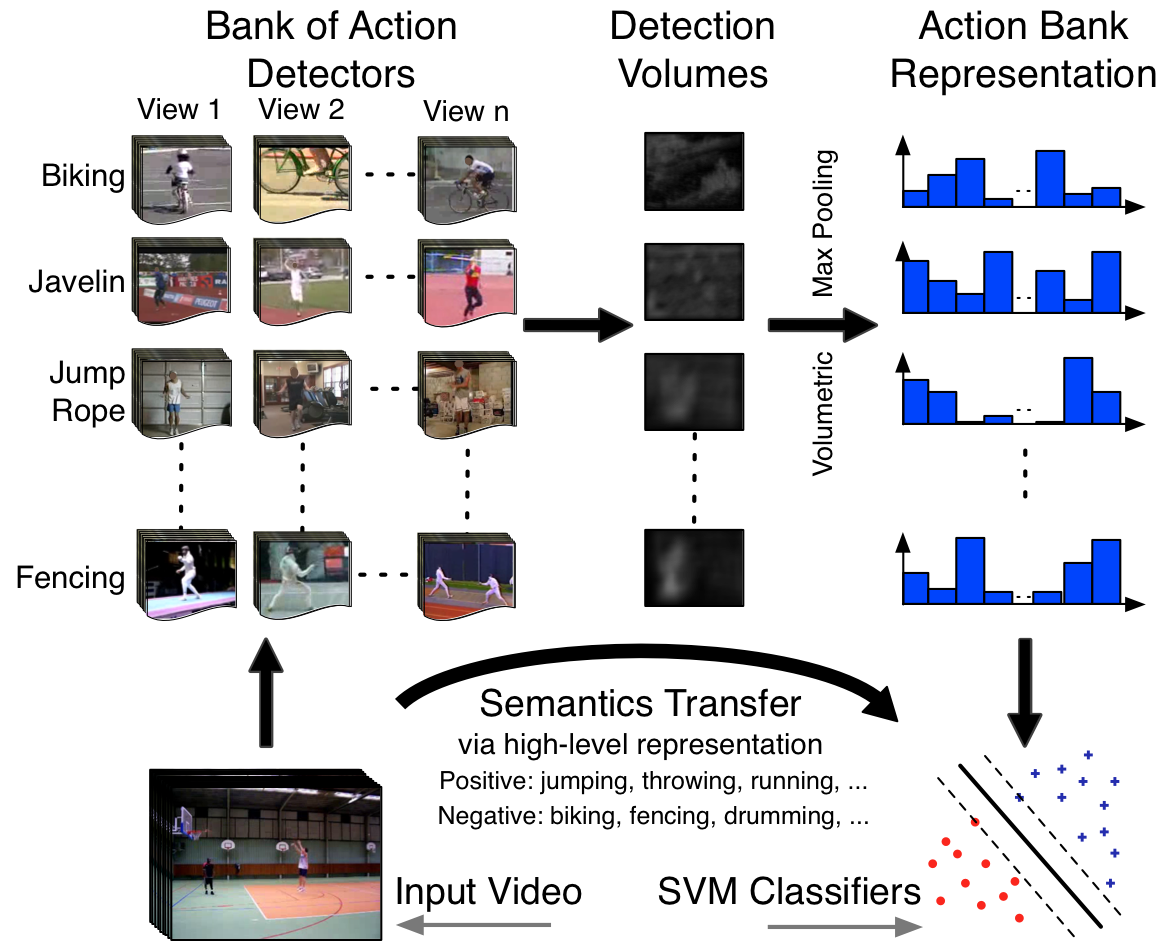 | Activity recognition in video is dominated by low- and mid-level features, and while demonstrably capable, by nature, these features carry little semantic meaning. Inspired by the recent object bank approach to image representation, we present Action Bank, a new high-level representation of video. Action bank is comprised of many individual action detectors sampled broadly in semantic space as well as viewpoint space. Our representation is constructed to be semantically rich and even when paired with simple linear SVM classifiers is capable of highly discriminative performance. We have tested action bank on four major activity recognition benchmarks. In all cases, our performance is significantly better than the state of the art, namely 98.2% on KTH (better by 3.3%), 95.0% on UCF Sports (better by 3.7%), 76.4% on UCF50 (baseline is 47.9%), and 38.0% on HMDB51 (baseline is 23.2%). Furthermore, when we analyze the classifiers, we find strong transfer of semantics from the constituent action detectors to the bank classifier.
|
|
S. Sadanand and J. J. Corso.
Action bank: A high-level representation of activity in video.
In Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, 2012.
[ bib |
code |
project |
.pdf ]
|
More information, data and code are available at the project page. |
|
Dynamic Pose for Human Activity Recognition  | Recent work in human activity recognition has focused on bottom-up approaches that rely on spatiotemporal features, both dense and sparse. In contrast, articulated motion, which naturally incorporates explicit human action information, has not been heavily studied; a fact likely due to the inherent challenge in modeling and inferring articulated human motion from video. However, recent developments in data-driven human pose estimation have made it plausible. In this work, we extend these developments with a new middle-level representation called dynamic pose that couples the local motion information directly and in- dependently with human skeletal pose, and present an appropriate distance function on the dynamic poses. We demonstrate the representative power of dynamic pose over raw skeletal pose in an activity recognition setting, using simple codebook matching and support vector machines as the classifier. Our results conclusively demonstrate that dynamic pose is a more powerful representation of human action than skeletal pose.
|
|
R. Xu, P. Agarwal, S. Kumar, V. N. Krovi, and J. J. Corso.
Combining skeletal pose with local motion for human activity
recognition.
In Proceedings of VII Conference on Articulated Motion and
Deformable Objects, 2012.
[ bib |
slides |
.pdf ]
|
|
|
|
