Welcome, readers of the June 2014 Chess Life
article.
Two accessible recent professional papers on my work are
here
and here, as well as
four
GLL
blog
posts.
For details of my methodology, including the substantial scientific
control-checking, see my Jan. 13, 2013
open letter and report on the Ivanov
case, and my "Control" screening-test data.
The FIDE-ACP anti-cheating proposals are linked from this June 8
story on ChessBase.com. The guidelines for using statistics are
written in a normative way that does not presuppose any particular
system, let alone mine.
My "Fidelity"
chess research site, my homepage,
and my chess page have
other links and information.
-
As I was giving my last answer in the NPR segment, I was aware that
"Fail-Safe" is a book and
movie like
"Dr. Strangelove." I also had in my head the recent
news
on the reduced statistical confidence in March's apparent confirmation of
predictions about gravity waves and cosmic inflation, mainly because the
modeling of dust in Earth's atmosphere may have been deficient. I'm still
shaking dust from my model too, but one difference is that whereas we don't
have a million Earths to use for comparison, we do have millions of chess
games.
-
The position shown on my laptop is from my own
analysis of the second Topalov-Kramnik 2006
match game. It exhibits a cryptic hash-table phenomenon with versions
of Fritz and several other engines, which you can reproduce for yourself
using a freely downloadable version of Toga II via
steps in my article
"Digital Butterflies and PRGs". Really quantifying this phenomenon
would require large-scale computing (and might come up empty); my anti-cheating
activities and other chess research have taken priority.
-
The quote by Jacques Derrida came from this
post
about the Asian tsunami disaster on the
Adventus blog.
I connected it in a Dec. 2006
e-mail impressing my reasons for asking help with the above hash-table
phenomenon; help came in 2007--08 from Toga II programmer Thomas Gaksch,
to whom I remain grateful for several things.
The quote also connects thematically
to something said by Derrida himself to a family member after a lecture.
-
Some small corrections (which I missed in fact-checking a draft):
my program is about 12,000 lines of C++ together with
about 3,500 lines of Perl scripts (some of the former and
over half the latter written by students); the cheating test operates
referencing the 8,500 moves from the 2005--08 WC events (which also
generate the IPR's) but was determined from over 500,000 moves in
games between players within 10-to-20 of an Elo century mark from
1600 to 2700; my neighbor's brother is a McGill departmental colleague of my
college friend Narendra Subramanian, with whom I toured England in 1980
before visiting Oxford on my extra day and
deciding I liked it. (To add to the closer-than-just-social network example with
Bob Sloan, he now has a joint paper with my Princeton
next-classmate and complexity colleague Judy Goldsmith---at the same
2014 Multidisciplinary Preference Handling workshop where my second chess
paper linked above is appearing.)
-
The day before the interview, I had just been contacted officially about the
case of Jens Kotainy, who is the player referenced in the "test results from
the German Bundesliga" line. I gave a formal report the next month conveying
the essence of the quotes in that paragraph, but Kotainy was still allowed
to play in the August 2013 Sparkassen Open. There he was caught with a
transmitting device in round 8---while from round 4 onward I was
alerting arbiters and my fellow FIDE-ACP committeemen to the growing
statistical positive. (The word "people" is general, not with reference
to the Bundesliga itself.)
- Answers to "20 Questions" from commenter
RichT in the Chess Life article.
By the way, no illusions about "catching" everyone. I did not know the
title to be used for the cover and online offering, but let's note that
one other meaning of "catching" is
intercepting, restraining. I grabbed a chess bag hurriedly before my 9:30am
class on the day of the photo shoot, then found it had an old set with
all the "pieces" visibly chipped except the Knights. They needed a
white piece against the black table, and since the Knight is after all my
favorite piece, I used it despite some inadvertent symbolism.
-
To answer generally some of the other comments in the article: Doing the analysis and tests
for my
1/13/13 Ivanov missive took 2 days,
while almost 2 weeks of care went into hearing and addressing the
legal and social concerns. To my mind the issue has subsequently
been sharpened by the
IMHO-unacceptable further incidents with Ivanov last fall, and with Jens
Kotainy not only at Dortmund but also earlier when players threatened to
boycott a Rapid tournament on-site unless he were barred, which he was.
The main questions I see are:
-
How does one avoid that kind of incident and prejudgment by other players
if one does not have a central process---in which the player can coherently
defend him/herself---or at least a private inquiry procedure?
-
Noting that my methods are public and re-testable (indeed our draft calls for
a second test to be done with another engine in case of sole positives),
what should one do if another 5.0+ (or two consecutive 3.55+es,
which amount to the same deviation) are found, by others not just "me"?
(Note that a single 3.55, which would be expected once a month if a
thousand players are active in tournaments at comparable levels each week,
means nothing in isolation.)
-
Can we assure effectiveness of the other measures in cases of a new
method, for instance visual decoding of positions by a hidden camera
linked by wire to a CPU plus muscle-buzzer, if stats-alone judgment is
foreclosed?
My setup is expressly against the notion that "if you go 9-0 in a
section you must be cheating." As I wrote in Annex C of the
ACC draft proposal published today (June 3) by FIDE, "the tests
must measure specific criteria, such as ..., so that a positive result has
more specific meaning than 'this person played unbelievably well'."
Most to the point, the great majority of my involvements (including all
from August 2007 to January 2011) have been giving results against
insinuations that players have made. Those who follow GM Arthur Kogan's
group on Facebook have seen me counter all insinuations
that have been made public; quite a few more have stayed private.
Nor will it see a "low Expert" performing at 2300 level as unusual.
Indeed, my error bars for IPR's over 9-game events by sub-2400 players
are usually over +- 200 Elo wide. So from 2050 to 2300 is "just random".
If the low expert gets to 2300 using a 3100-rated source, my model will
notice, but if he/she has a streak of motivation or just luck and plays like
a 2300 source, it will say "random". In one case a disputed prize was
awarded after my model said a low-2200's player performed at 2430 but gave
an under 1-sigma deviation in the formal tests.
(Moreover, the null-hypothesis methodology requires using the
rating-after as the parameter setting, not the "2050" rating-before.)
-
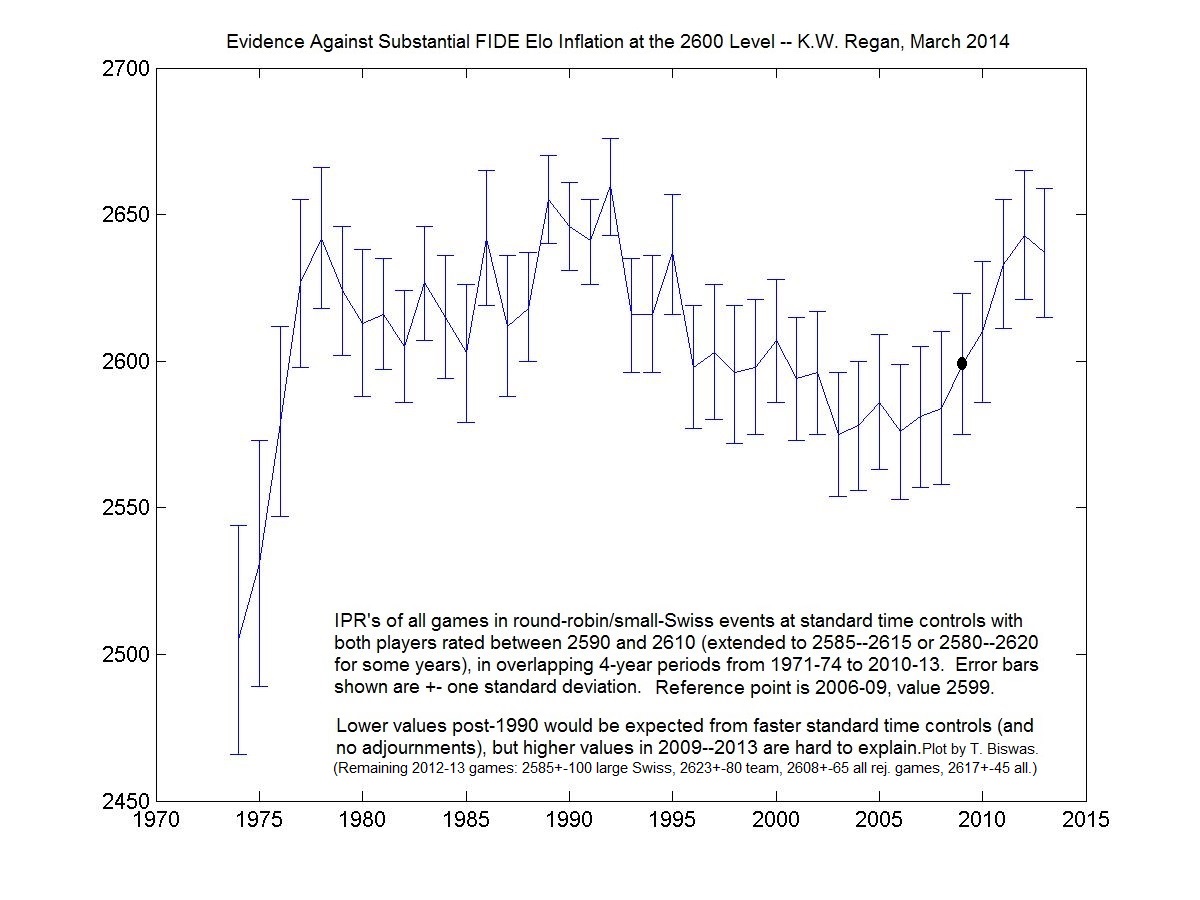
Here is a more-detailed version of Figure 6 in the article, which was
deemed too dense for print.
For a fresh example of "Intrinsic Performance Ratings",
here are the
IPRs for the 2014 US Championships (with a general note about stats and
interpretation at the bottom).
-
Elo 3600 (actually 3575) was technically the y-intercept of my
regression line against the player's "Average Error" (AE). The regression
is a strong linear fit, but possibly fooled by the tendency of logistic
curves to look straight for long middle sections---see diagrams in my
workshop paper. Since there is no unique definition of perfect play
at chess, what's meant by a 3600 ceiling is that no strategy would
consistently score over 90% against a suite of 3200-rated programs.
After the interview, getting a better handle on sub-2200 data and
incorporating results from Houdini 3 analysis caused me to lower what's
really a seesaw to a 3475 intercept, lifting 1600--1900 better into line,
but several factors including some "reverse engineering" of Houdini's
"calibrated evaluations" and data from the recent significantly improved
Komodo and Stockfish versions may shift it again. Near the middle of
the seesaw, 2200--2800, the differences are less. Getting more reliable
games by sub-2200 players would enable a logistic regression that might
point to a higher ceiling.
{kind=link}