CloudAQUA: An Analytic Research on Quantifying Availability (AQUA) for Cloud Resource Provisioning and AllocationResearch Focus Cloud computing will significantly transform the landscape of the IT industry and also impact the economy and society in many ways. The availability of cloud services, affected by various failures including inaccessibility of cloud resources, becomes increasingly more critical, as government agencies, business and people are expected to rely more and more on these services. According to a 2011 report by Emerson Network Power, on average, a service outage lasts about 134 minutes, and these service outages cost about $426 billion of loss worldwide. Additionally, 2012 global survey found that availability/reliability of cloud applications was cited by 67% of those surveyed as one of the top challenges for preventing a successful implementation of cloud services, followed by device based security (66%) and cloud application performance (60%). In order to cost-effectively provide a desired level of availability (e.g., 99%) for an application requiring say N VMs, an Infrastructure-as-a-Service (IaaS) provider needs a middleware to determine the minimum number of backup VMs, say K, to be provisioned, and in addition, how these (N+K) are placed (or mapped) to the servers, as well as other servers and VM management strategies (e.g., when to power- on servers with the backup VMs etc.). In turn, the middleware needs an efficient model to predict the availability that can be achieved for a given N, K and other system settings. In particular, the middleware will need a comprehensive knowledge of the failure characteristics of the physical components such as servers and switches including their mean-time-between-failure (MTBF) and mean-time-to-repair (or replacement) (MTTR) and in particular, how the failures may be correlated temporally and spatially. Despite a body of recent work on reporting/characterizing failures in datacenters, there still lacks a comprehensive and publicly accessible failure data set for use by researchers in academia/universities. In addition, although there exist some heuristics to qualitatively improve availability using e.g., triple duplication, and methods to measure the availability in a post-priori fashion, to the best of our knowledge, there exists no quantitative tools, including analytic models, to accurately predict the availability, let alone any methods to determine the optimal VM provisioning and allocation (placement) to achieve a given availability level. The cloudAQUA project is funded by the National Science Foundation ("An Analytical Approach to Quantifying Availability (AQUA) for Cloud Resource Provisioning and Allocation". 2014 - 2016. National Science Foundation (NSF), CSR Medium Collaborative Research Award # 1409809) and is inspired and built upon the research project sponsored by Google ("Disaster Resilience and Availability Prediction (DRAP) for Clouds", Google Research Awards, Award # 2011_R2_549, 2011 - 2012). Google's interests in achieving a (minimum) level of availability for certain cloud services / applications arise from the fact these cloud services require a quorum provided by at least N running Virtual Machines. Google researchers who sponsored the project have not only guided our work but also provided several useful insights including the need to consider correlated (or cascaded) failures of servers and switches/routers (one must realize that Google can't provide any detailed physical component failure data or application performance requirements to academic researchers). Their suggested future work has helped shape the scope and approaches of our current work. This research takes a holistic approach to meeting a required availability level for a given cloud application or (service) by
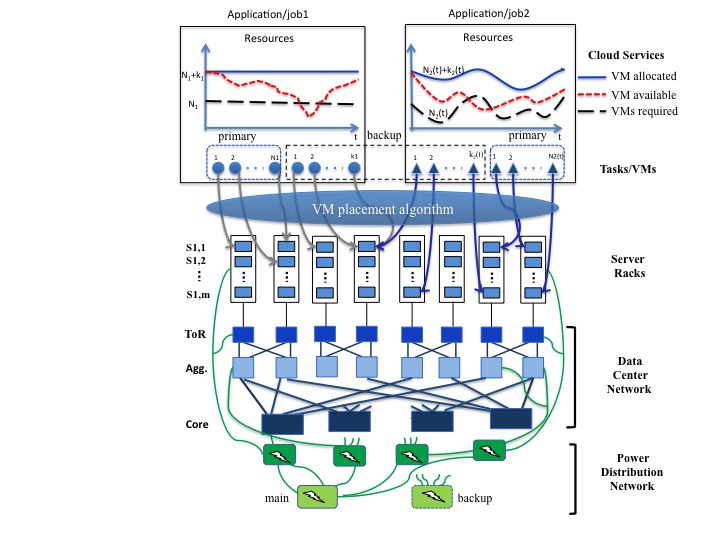
The overall system model under study is illustrated in the diagram below. Specifically, we consider two types of applications/jobs:
| |