Recitation 8
Recitation notes for the week of October 15, 2025.
Minimizing Maximum Lateness
This problem is relevant to HW 4, Q3!
We will not cover the minimizing maximum lateness problem in any detail in class. Please read up the care package on this problem.
Problem Statement
Here is a quick recap of the problem statement:

Input Instance
Here is an example input to the problem:
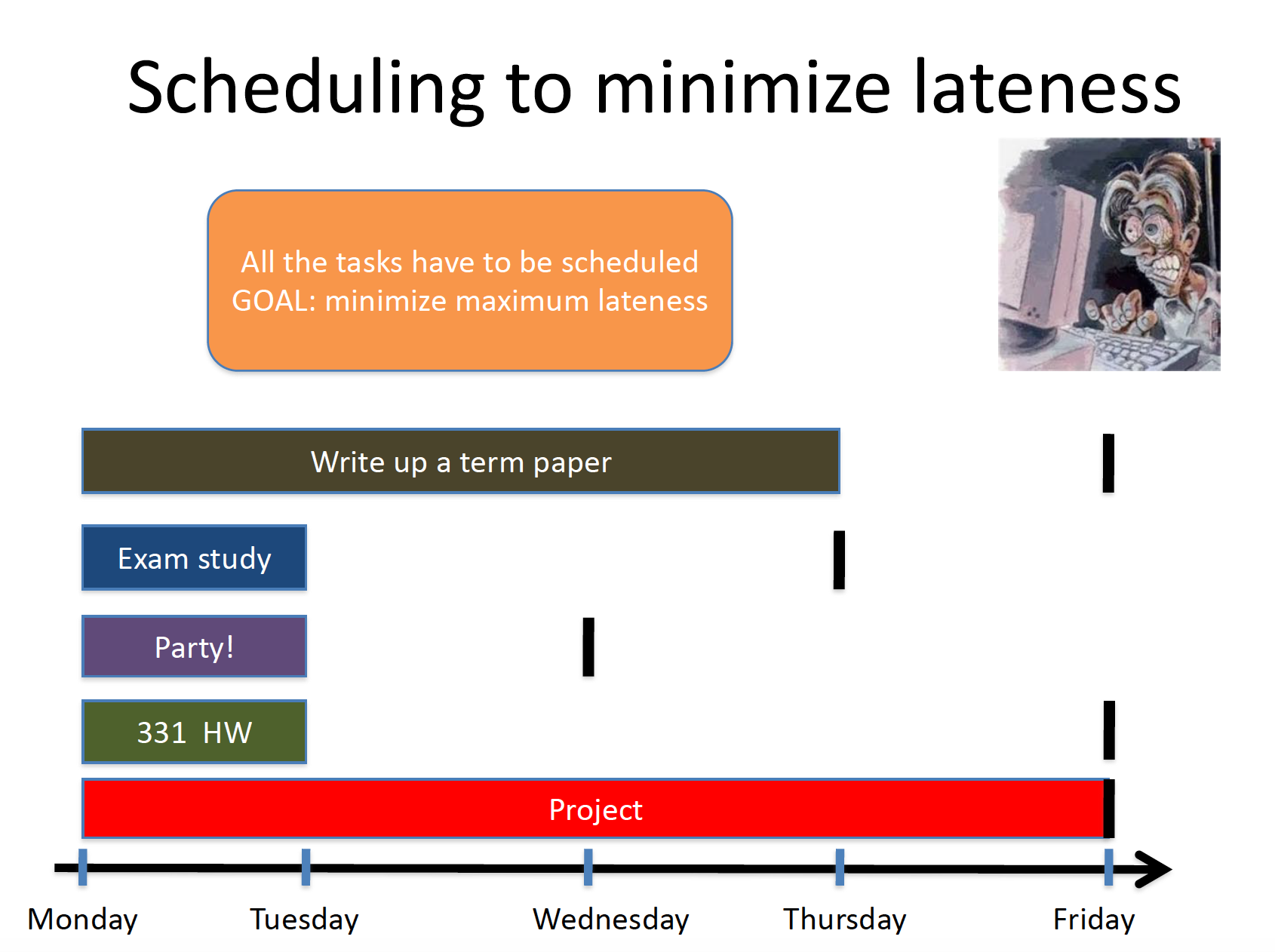
Greedy Algorithm
Here is the greedy algorithm to solve the problem:

Exercise
Run the greedy algorithm on the above instance and calculate lateness of each job (assuming one breaks ties for jobs with "Friday" as deadline in order 331 HW, Write up a term paper and Project) and compute the final maximum lateness (which should be $6$ for Project job).
HW 4, Question 1
We begin by restating the problem statement:
The Problem
We come back to the issue of many USA regions not having high speed internet. In this question, you will consider an algorithmic problem that you would need to solve to help out a (fictional) place get high speed Internet.
You are the algorithms whiz in the effort to bring high speed Internet to SomePlaceInUSA. After lots of rounds of discussions and public feedback, it was decided that the most cost-effective way to bring high speed internet to SomePlaceInUSA was to install high speed cell towers to connect all houses in SomePlaceInUSA to high speed internet. There are two things in your favor:
- It just so happens that all of the $n$ houses in
SomePlaceInUSAare on the side of a straight road that runs through the town. - The above implies that you only need cell towers that only need to broadcast their signal in a narrow range, which means one cell tower can provide high speed internet access to all houses within $100$ miles ahead (rather than the usual 45 mile range ) on the road from its location (we are assuming that these cell towers will be on the side of the road). These cell towers are unidirectional so they can provide connection to only houses that are ahead of it.
None of your team-mates attended the class on greedy algorithms, so in this problem you will design an efficient algorithm for them, which your team can use to figure out which houses should have cell towers installed next to them so as to use the minimum number of cell towers.
With an eye on the future, the cell towers have to be placed so that there is continuous cell coverage on the road from the first and the last house on the road. I.e. it should never be the case that you are on the road (between the first and the last house) such that you are
strictly more than $100$ miles ahead of the closest cell tower. You can assume that you have to put a cell tower at the first house on the road in SomePlaceInUSA and that this tower is the only one capable of providing coverage to the house next to it. All other towers can only provide coverage to the houses in front of and not beside them.
Note
You should assume the following for your algorithm:
- No two consecutive houses are more than $99$ miles apart. Note that this implies there always exists a feasible way to assign cell towers to houses. Further, note that houses can be much closer than $99$ miles to each other.
- The input to your algorithm is a list of houses along with their distance (in miles) from the very first house. You cannot assume that this list is sorted in any way.
Here are the two two parts of the problem:
- Part (a): Assume that we relax the condition that the cell towers have to be next to house: i.e. you can place a cell tower anywhere on the road (the $100$ mile coverage restriction on the cell towers still applies). Design an $O(n)$ time algorithm to solve this related problem.
- Part (b): Design an $O(n\log{n})$ time algorithm to solve the original problem (i.e. where the cell towers have to be next to a house). Prove the correctness of your algorithm and analyze its running time.
We begin with an example input to show the solutions to both part (a) and (b) (and in particular, pointing out why solving part (a) does not solve part (b)):
Sample Input/Outputs
- Input:
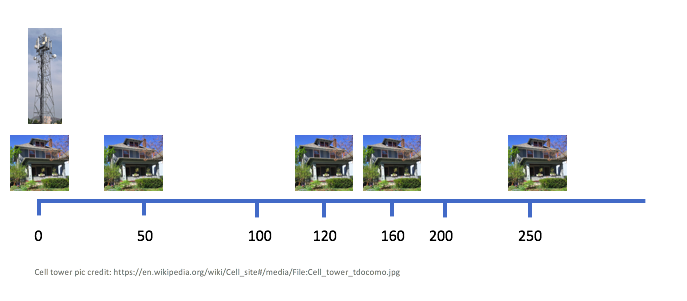
In the above $n=5$ and we have a cell tower at the first house since that is mandated by the problem. Also note that any two consecutive houses are at most $99$ miles apart (actually the largest distance in the above is $90$ miles). Note that in this case a valid input your algorithm should handle is $[ (1, 120), (2, 50), (3, 250), (4, 160) ]$, where in each pair the first index refers to a house (so in the example above the houses in order are $2,1,4,3$) and the second element of a pair is the distance in miles from the first house.
- Solution for part (a): Here is an optimal solution for part (a) for the above input:
-soln.png)
Here is a quick visual argument for the above leads to continuous cell coverage:
-cover.png)
We will see shortly that this is an optimal assignment for part (a).
- Solution for part (b): Here is an optimal solution for part (b) for the above input:
-soln.png)
Here is a quick visual argument for the above leads to continuous cell coverage:
-cover.png)
We will not prove it, but this is an optimal assignment for part (b).
Part (a)
Algorithm Idea
The idea is very simple: since we do not have any restriction on where the cell towers can be placed: we will place them at multiple of $100$ mile marks until there is continuous coverage from the first to the last house.
Even though it is not needed for the HW submission
We provide the algorithm details and proof of correctness idea below for your convenience.
Algorithm Details
//Input is (h1,d1), ... , (hn-1,dn-1)
// di is the distance of house hi from the first house
dmax= max(d1, ... ,dn-1)
d=0 //Assuming the first house is at mile 0
while( d < dmax)
Place a tower at mile d
d += 100
Proof (of Correctness) Idea
First note that the algorithm above places $\left\lceil \frac{d_{\max}}{100}\right\rceil$ many cell towers.
To complete the proof, we claim that any valid placement of towers must place at least $\left\lceil \frac{d_{\max}}{100}\right\rceil$ cell towers. For the sake of contradiction assume that we are able to come up with a valid placement with \[\le \left\lceil \frac{d_{\max}}{100}\right\rceil -1 < \frac{d_{\max}}{100}\] cell towers. Since each cell tower can cover $100$ miles, this means that the total number of miles covered will be \[<100\cdot \left(\frac{d_{\max}}{100}\right) = d_{\max},\] which means at least $1$ mile from the first house and the last house does not have cell coverage, which means that our placement was not valid.
Runtime analysis
We will assume the following, which you need to prove on your own:
Exercise 1
\[d_{\max}\le 99n.\]
while runs for at most $99n/100\le n$ times. Each iteration takes $O(1)$ time: so overall the loop takes $O(n)$ time. Since computing $d_{\max}$ takes $O(n)$ time, the overall runtime is $O(n)$, as desired.
Part (b)
We would like to point out two things:
- The algorithm above for part (a) does not work for part (b). The basic idea is that the algorithm from part
(a) can place a cell tower at a mile where there is no house but for part (b) the cell towers have to be at a house. See the sample input/output above for a concrete example. - Think how you could modify the algorithm for part (a) could be modified to handle the extra restriction that the cell towers have to placed next to a house.
Hint
Think of a greedy way to decide on which houses to pick for cell tower installation. It might help to forget about the scheduling algorithms we have seen in class and just think of a greedy algorithm from "scratch." Then try to analyze the algorithm using similar arguments to one we have seen in class.
Note
The proof idea for part (a) does not work for part (b): you are encouraged to use greedy stays ahead technique we have seen in class to prove correctness of a greedy algorithm.
Greedy Stays Ahead
We briefly (re)state the greedy stays ahead technique in a generic way (and illustrate it with the proof of the greedy algorithm for the interval scheduling problem that we saw in class).
Roughly speaking the greedy stays ahead technique has the following steps:
Sync up partial greedy and optimal solutionGreedy algorithms almost always build up the final solution iteratively. In other words, at the end of iteration $\ell$, the algorithm has computed a `partial' solution $\texttt{Greedy}(\ell)$. The trick is to somehow `order' the optimal solution so that one can have a corresponding `partial' optimal solution $\texttt{Opt}(\ell)$ as well.Define a 'progress' measureFor each iteration $\ell$ (as defined above), we pick a 'progress' measure $P(\cdot)$ so that $P\left(\texttt{Greedy}(\ell)\right)$ and $P\left(\texttt{Opt}(\ell)\right)$ are well-defined. This is the step that is probably most vague but that is by necessity-- the definition of the progress measure has to be specific to the problem so it is hard to specify generically.Argue 'Greedy Stays Ahead' (as per the progress measure)Now prove that for every iteration $\ell$, we have \[P\left(\texttt{Greedy}(\ell)\right) \ge P\left(\texttt{Opt}(\ell)\right).\]Connect 'Greedy Stays Ahead' to showing the greedy algorithm is optimal. Finally, prove that with the specific interpretation of 'Greedy Stays Ahead' as above, at the end of the run of the greedy algorithm the final output is 'just as good' as the optimal solution. Note that the progress measure $P(\cdot)$ need not be the objective function that the greedy algorithm is trying to minimize (indeed this will not be true in most cases) so you will still have to argue another step to show that greedy stays ahead indeed implies that the greedy solution is no worse than the optimal one.
Next, we illustrate the above framework with the proof we saw in class that showed that the greedy algorithm for the interval scheduling problem was optimal:
Sync up partial greedy and optimal solutionWe did this by ordering the intervals in both the greedy and optimal solution in non-decreasing order of their finish time. Specifically, recall that we defined the greedy solution as \[S^*=\left\{i_1,\dots,i_k\right\}\] and an optimal solution as \[\mathcal O=\left\{j_1,\dots,j_m\right\},\] where $f(i_1)\le \cdots \le f_(i_k)$ and $f(j_1)\le \cdots f(j_m)$. With this understanding, the 'partial' solutions are defined as follows for every $1\le \ell\le k$: \[\texttt{Greedy}(\ell)=\left\{i_1,\dots,i_\ell\right\}\] and \[\texttt{Opt}(\ell)=\left\{j_1,\dots,j_\ell\right\}.\]Define a 'progress' measure. We define the progress measure as the (negation of) finish time of the last element in the partial solution, i.e. \[P\left(\texttt{Greedy}(\ell)\right) = -f\left(i_\ell\right)\] and \[P\left(\texttt{Opt}(\ell)\right) = - f\left(j_\ell\right).\] Two comments:- If the "$-$" sign in the definition of $P(\cdot)$ is throwing you off-- it's for a syntactic reason (and it'll become clear in the next step why this makes sense).
- Note that the progress measure above has nothing (directly) to do with the objective function of the problem (which is to maximize the number of intervals picked).
Argue 'Greedy Stays Ahead' (as per the progress measure). In class, we proved a lemma that stays that for every $1\le \ell\le k$, we have \[f\left(i_\ell\right)\le f\left(j_\ell\right).\] Note that this implies that for our progress measure (and this is why we had the negative sign when defining the progress measure), for every $1\le \ell\le k$, \[P\left(\texttt{Greedy}(\ell)\right) \ge P\left(\texttt{Opt}(\ell)\right),\] as desired.Connect 'Greedy Stays Ahead' to showing the greedy algorithm is optimal. For this step, we have a separate proof that assumed that if the 'Greedy Stays Ahead' lemma is true then $\left|S^*\right|\ge \left|\mathcal{O}\right|$.
A warning
Please note that while the above 4-step framework for the 'Greedy Stays Ahead' techniques works in many cases, there is no guarantee that this framework will always work, i.e. your mileage might vary.
HW 4, Question 2
Speedy Skate
There are $n$ skaters, where each skater $i$ has a triple $(s_i,p_i,d_i)$. $s_i,p_i$ and $d_i$ are the times needed by skater $i$ for their skate, post workout and drive parts of the competition. They have to do the three parts in order: skate first, then post workout and then drive back to their hotel/home. Only one skater can skate in the rink at a time but there is no such restriction on post-workout and driving (i.e. if possible all skaters can post-workout/drive in "parallel"). Your goal is to schedule the skaters: i.e. the order in which the skaters start their skate part so that the completion time of the last skater is minimized. I.e. you should come up with a schedule such that all skaters finish their competition as soon as possible.
Sample Input/Outputs
- Input:
Say the input is $[(2,2,3),(1,3,4)]$, i.e. we have $s_1=2,p_1=2,d_1=3$ and $s_2=1,p_2=3,d_2=4$.
- Output:
Let us work this one out. There are only two schedules $1,2$ and $2,1$. So we consider both in turn:
- So assume skater $1$ starts at time $0$. They will get out of the skate rink at time $0+s_1=2$, will finish post-workout at the end of time $2+p_1=4$ and be done with the competition at the end of time $4+d_1=7$. On the other hand, skater $2$ starts at time $2$ (this is when skater $1$ is out of the skate rink). Skater $2$ will get out of the skate rink at time $2+s_2=3$, will finish post-workout stretching at time $3+p_2=6$ and will be done with the competition at $6+d_2=10$. Thus, the completion time of this schedule is $\max(7,10)=10$.
- Let us now consider the second schedule. In this case skater $2$ starts first and finishes at time $0+1+3+4=8$ and skater $1$ starts at time $1$ and finishes at $1+2+2+3=8$. Thus, the completion time in this case is $\max(8,8)=8$.
Part (a)
Here we have to argue that there is always an optimal solution with no idle time: i.e. there should be no gap between when a skater finishes their skate and when the next skater starts their skate.
Proof Idea
Assume that skater $i$ has start time $st_i$. Note we want to argue that for every $i$, $st_{i+1}=st_i+s_i$. If this condition is satisfied for all $i$, then we are done. So assume not. We will now show how to convert this into another set of start times $st'_i$ for every skater $i$ that has no idle time and the resulting schedule is still optimal. Repeat the following until there exists a skater $i$ such that $st_{i+1}> st_i+s_i$; update $st_{i+1}=st_i+s_i$. Once this procedure stops, let $st'_i$ be the final start time of skater $i$.
Let $f_i=st_i+s_i+p_i+d_i$ be the original finish time for skater $i$ and let $f'_i=st'_i+s_i+p_i+d_i$ be the new finish time. Then one can argue by induction that (and this is your exercise):
Exercise 2
For every skater $i$, $f'_i\le f_i$.
Part (b)
Note
Part (a) actually then shows that we only need to figure out the order of the skaters: once that is set, the start times are automatically fixed. Hence for part (b), one just needs to output the ordering among the skaters.
In this part you have to come up with an efficient (i.e. polynomial time) algorithm to come up with an optimal schedule for the skaters that minimizes the completion time. We repeat the following note and hint from the problem statement:
Note
As has been mentioned earlier, in many real life problems, not all parameters are equally important. Also sometimes it might make sense to "combine" two parameters into one. Keep these in mind when tackling this problem.
Hint
In the solution that we have in mind, the analysis of the algorithm's correctness follows the exchange argument. Of course that does not mean it cannot be proven in another way.
Exchange Argument for Minimizing Max Lateness
Main Idea
If we have a schedule with no idle time and with an inversion, then we can rid of an inversion in such a way that will not increase the max lateness of the schedule.
Recall
In (4.8) in the book, we showed that schedules with no inversions and no idle time have the same max lateness.
Given the schedule below where the deadline of $j$ comes before the deadline of $i$ (the top schedule has an inversion):
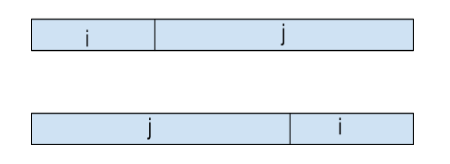
Let us consider what happens when we go from top schedule to the bottom schedule. Obviously $j$ will finish earlier so it will not increase the max lateness, but what about $i$? Now $i$ is super late.
However, note that $i$’s lateness is $f(j) - d(i)$ where $f(j)$ is the finish time of $j$ in the top schedule. Now note that \[f(j) - d(i) < f(j) - d(j),\] so the swap does not increase maximum lateness.
An Example
Here is an explicit example showing the above proof argument: \[d(a) = 2~~~~ t(a) = 1\] \[d(b) = 5~~~~ t(b) = 6\] \[d(c) = 8~~~~ t(c) = 3\]
Now consider this schedule with inversions: \[__a__|____c____|______b_______\] And another schedule without inversions: \[__a__|______b_______|____c____\]
The first schedule has max lateness of $5$ while the second schedule has max lateness of $2$.
NOTE
Examples do not suffice as proofs. But they are good for understanding purposes.