CSE668 Principles
of Animate Vision Spring 2011
5. Purposive vision paradigms
Marr paradigm of task-independent, disembodied
"vision as recovery", we will next consider the newer
"active" approach to extracting useful information from
3-D and motion image sequences. There are several
names different research groups give to this
approach,
which emphasize different aspects:
* purposive vision
* animate vision
*
active
vision
We will begin by reviewing three important papers which
lay out the conceptual schemes, or paradigms, that underlie
these
newer approaches. They have much in common, as we will
see. Together they define a common view of how to improve on
the passive, recovery-based paradigm that dominated
computer vision for so many years.
CSE668
Sp2011 Peter Scott 07-01
Fermuller
and
Aloimonos,
Vision
and
action, Image and
Vision Computing v
13
(1995) 725-744. Required
reading.
The
two basic theses of this paper:
1.
What is vision?
It is not recovery (the construction of a quantitative
3-D
world
model
of
all possible object indentifications
and localizations. It is the process of acquiring task-directed
visual information and then acting. Vision exists to
to
support
behavior.
2. Vision is intimately linked with the observing entity,
its goals and physical capabilities. It is goal-directed
behavior which can be understood only in the context of
the physical "details" of the observer. Vision is
embodied
and goal-directed.
Eg: The vision of a flying insect will have different
representations, algorithms and decision processes
than that of a human. Likewise, the vision of a human
and a robot welder, or a robot welder and a Mars
rover vehicle.
CSE668 Sp2011 Peter Scott 07-02
In
an nutshell, a common element of these recent research
approaches is that the goal of vision is not to see but to
do. Aspects of vision which, in a given embodiment and
task environment, do not support action (behaviors) should
not
be supported.
A
quick
review
of
the
Marr paradigm
David
Marr, a British mathematician and neuroscientist
on
the faculty of MIT, proposed, in a very influential
1982 book "Vision: a computational investigation into
the human representation and processing of visual infor-
mation," that vision is a process of creating a full and
accurate world model of the visually accessible world
through quantitative recovery. Vision can be understood,
Marr proposed, outside the specifics of task or embodi-
ment.
There is "vision," according to Marr, not "visions."
CSE668 Sp2011 Peter Scott 07-02a
His paradigm decomposed the study of vision into three
heirarchical
levels:
* Theory
* Algorithms
*
Representations
The algorithms for tracking, for instance, in a frog
hunting insects should be similar to those of a mother
deer
watching her fawns running through a meadow.
CSE668 Sp2011 Peter Scott 07-03
Marr believed
it was very important to separate the
three
heirarchical levels and to analyze them top-down
and
independently. First
determine the theory for some
operation, then
see what algorithms satisfy that theory,
then determine
the representations that are most efficient
for those
algorithms.
At
the theory level, Marr defined three stages in the
process
of transforming data on the retina into visual
awareness
of the 3-D world:
*
Creation
of
a
"primal sketch"
*
Mapping
the
primal
sketch into a "2 1/2-D sketch"
*
Mapping
the
2
1/2-D sketch into a 3-D world model
The primal
sketch extracts key features, such as edges,
colors
and segments. The 2 1/2-D sketch
overlays the
primal
sketch with secondary features: shading, texture, etc.
The
3-D world model is the fully recovered scene.
CSE668 Sp2011 Peter Scott 07-03a
Where
are the problems in the Marr paradigm?
* Disembodied: inefficient, ineffective
* Heirarchical: non-adaptive, non-feedback,
non-learning
*
Quantitative
recovery:
non-robust,
unstable.
We next turn to the active vision approach of Fermuller and
Aloimonos to
see if these problems can be addressed through
their paradigm.
CSE668 Sp2011 Peter Scott 07-04
Fermuller-Aloimonos'
Modular View of
an active vision system
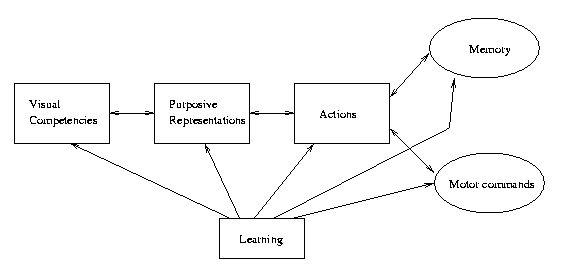
Each visual competency is a skill needed to complete some
task or set of tasks. The purposive representations are
data structures as simple as they can be yet effectively
supporting
a linked competency.
Eg: Obstacle avoidance is a basic visual competency.
A purposive representation for this competency needs
to
include
some
measure
of visual proximity.
CSE668 Sp2011 Peter Scott 07-05
The Fermuller-Aloimonos paradigm laid out in this paper
is a "synthetic" approach: start by defining the simplest
goals and competencies, embody them, link them with
learning. Then add a new layer of competencies on top
of
the existing set for a given embodiment.
Competencies
These should be understood as skills for recognition
not
recovery.
Eg: For obstacle avoidance we need to recognize
which object points are getting closer to us,
threating us. We don't need to know how many
mm
away
they
are
or their quantitative velocity.
This distiction is very important, for it puts the
qualitative procedures of pattern recognition at the
center of the action, not the quantitative procedures
of metric mapping. So the right question for determining
representations and algorithms is: what do we need to
know about the
object
to label it properly guide us to
take the right
action?
CSE668 Sp2011 Peter Scott 07-06
Their
"Heirarchy of Competencies: "
Motion Compencies
* Egomotion estimation
* Object translational direction
* Independent motion detection
* Obstacle avoidance
* Tracking
* Homing
Form (Shape) Competencies
* Segmentation
* 2-D boundary shape detection
* Localized 2-1/2-D qualitative patch maps
* Multi-view
integrated ordinal depth maps
CSE668 Sp2011 Peter Scott 07-07
Note that the
Motion Competencies preceed the Form
Competencies.
In their view, we need to be able to
understand
motion before we can understand shape.
The
basic principle of the form competencies is that
shapes
can be represented locally and qualitatively.
Eg:
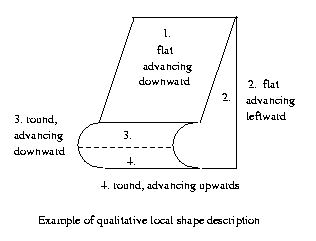
CSE668 Sp2011 Peter Scott 07-08
Finally,
there are the Space Competencies
* View-centered recognition and localization
* Object-centered recognition and localization
* Action-centered recognition and localization
* Object
relationship awareness
These are on the top of the heirarchy of competencies,
since they involve interpretations of spatio-temporal
arrangements of shapes.
CSE668 Sp2011 Peter Scott 07-09
Ballard,
Animate
Vision,
Artificial
Intelligence
v 48
(1991)
57-86.
Required
reading.
Dana Ballard, working at U of Rochester, had a similar
conception of how to get past the recovery roadblock.
He called his paradigm animate vision, that is, vision
with
strong anthropomorphic features. These include
* Binocularity
* Foveas
*
Gaze
control
By refusing to study monocular systems in blocks-world
settings, Ballard emphasized that interaction with the
environment produced additional constraints that could
be
used to solve vision problems.
CSE668 Sp2011 Peter Scott 07-10
Eg: Computation of kinetic depth (motion parallax).
This requires binocularity and gaze control.
Move the camera laterally while maintaining
fixation on a point X. Points in front of X
move in opposite direction to points behind X,
with apparent velocities proportional to depth
difference
with
X.
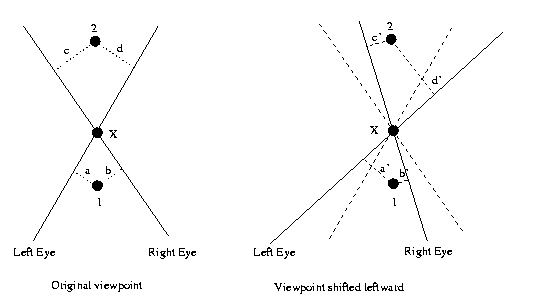
Point 1 appears to have moved to the right, since
a'>a and b'<b (right disparity of left eye has
increased, left disparity of right eye decreased).
Its
the
opposite
for
Point 2.
CSE668 Sp2011 Peter Scott 07-11
So to tell which of two points is farther away
in depth, fixate one and move your head laterally.
See if the other point moves in same or opposite
direction.
Using kinetic depth, the problem of depth estimation
becomes much simpler (compared to shape-from-shading
or other shape-from methods) with a lateral-head
movement because we can add a constraint to each
object
point P (in fixation coordinates)
zP = k ||dP||/||dC||
where zp is the depth of point P, dP is the displace-
ment vector of P in the fixation plane, and dC is the
displacement vector of the camera projected into the
fixation
plane.
CSE668 Sp2011 Peter Scott 07-12
Animate vision paradigm: Visual processing is built
on animate behaviors and anthropomorphic features.
Fixation frames and indexical reference lead to
compact representations. Note: fixation frame means
placing the origin of the coordinate system at the
point you are looking at or "fixating;" indexical
reference means indexing views by their most important
features,
discarding unnecessary visual detail.
Advantages
mentioned by Ballard:
* More efficient for search
* Can represent controlled camera motions well
*
Can
use
fixation
and object-centered frames
Note that a fixation frame has its coordinate center
at the fixation point, while object-centered frame
has its coordinates centered on the object even as
your
fixation point changes.
CSE668 Sp2011 Peter Scott 07-13
* Can use qualitative rather than quantitative
representations
and
algorithms
Eg: for collision avoidance, only have to worry about
objects "in front of" other objects. Don't need
a
metric
scale.
*
Can
isolate
a
region of interest preattentively.
Eg: Using head-motion induced blur, can find a fixation
ROI easily (object points near the fixation point
in
three-space).
* Exocentric frames (object, fixation) are efficient
for recognition and tracking.
* Foveal cameras yield low-dimensional images for
given
FOV
and
maximum
resolution.
CSE668 Sp2011 Peter Scott 07-14
* Active vision permits use of the world as a
memory
cache.
Eg: You see a book on the desk. Rather than memorize
its title, you just need to recall where the book
is. When you need the title, you can "look it up"
in
the
cache
by
gazing at it once again.
Eg: You want to decide if an aircraft you are looking
at matches a photograph. You quickly scan the
aircraft, noting where the insignia is, where the
engine intakes are, where the cockpit is. Then
you look at the photograph, memorize the insignia,
then go to your "indexically referenced" aircraft
view and compare the insignias. Repeat for the
other
key
features,
indexed
by location.
CSE668 Sp2011 Peter Scott 07-15
Visual
behaviors
Just as lateral head movement simplifies depth estimation,
other motions simplify other visual processes. These
motions
are called visual
behaviors.
Eg: Fixate on a point you are trying to touch, and hold
the fixation while you move your finger. If the
relative disparity decreases, you are getting closer.
Can think of this exploratory finger motion as
sampling
a
fixation
frame
relative disparity map.
So the animate vision approach is that for different tasks
and different embodiments we should engage different
visual behaviors. Each distinct visual behavior then
evokes
distinct compatible representations and constraints.
Eg: Fixation frame relative disparity map for hand-eye
coordination vs. indexical reference map for object
recognition.
CSE668 Sp2011 Peter Scott 07-16
Visual behaviors can use very simple representations, for
instance
color and texture maps.
Eg:
Texture homing. Fixate a region with a given texture.
Eg:
Color homing, edge homing.
The visual behavior of texture homing can be done, for
instance, by finding the sign of the gradient of the match
score of the present view and the desired texture as
fixation changes. Then using that one-bit representation
to
guide future saccades (eye movements).
Can divide most visual processes into "what" and "where"
tasks, recognize and locate. Visual behaviors make both
what
and where searches more efficient.
* What: indexical reference
*
Where:
low-dimensional
visual
search representations
CSE668 Sp2011 Peter Scott 07-17
Aloimonos,
Weiss
and
Bandyopadhyay,
"Active
Vision,"
Int. J. of Computer Vision, v 1 (1988), 333-356.
Required
reading.
While this paper was not the first to consider the
combination of perception and intentional behavior
that became known as active vision, it probably
had more impact than any of the other early papers
because of its strong claims for this area. These
claims
are summarized in Table 1 from the paper:
Problem
Passive
Observer
Active
Observer
-------
----------------
---------------
Shape from Ill-posed, needs to be Well posed, linear,
shading regularized. Even then stable.
no
unique
soln
(nonlin).
Shape from Ill-posed, hard to Well posed, unique
contour
regularize.
solns
(mono,
bino).
Shape from Ill-posed, needs added Well posed.
texture
assumptions.
Structure Unstable, nonlinear. Stable, quadratic.
from
motion
Optic flow Ill-posed, needs to be Well posed, unique
regularized. Regular- solution.
ization
dangerous.
CSE668 Sp2011 Peter Scott 07-18
The paper goes on to justify each of these claims by
mathematical analysis. We will not have time to discuss
the analysis, but you should at least read it over to
familiarize
yourself with the arguments.
Their bottom line: "... controlled motion of the
viewing parameters uniquely computes shape and
motion."
In the 15 yrs since this paper was published, the area
of active vision has become the dominant paradigm in
some important vision applications areas (eg. robotics,
autonomous vehicle navigation) because some of the
claims above have proven out in practice. But there are
hidden difficulties also... for instance, how do you
build an intelligent camera platform to execute desired
CSE668 Sp2011 Peter Scott 07-18a
Note: The definition of a well-posed problem in applied
mathematics, due to the French mathematician Hadamard, is
one which has these three properties:
1. It has a solution;
2. The solution is unique:
3. The solution depends continuously on data and parameters.
He argues persuasively that only well-posed problems have
solutions which are of practical value in the real world. Any
problem which is not well-posed is said to be ill-posed.
Eg: 1. x2+a=0, xεR, -1<a<-2, is ill-posed (multiple solutions)
2. x2+a=0, xεR, +1<a<+2, is ill-posed (no solutions)
3. y=x+1 x,yεR, 0<a<+2, is ill-posed (solution not contin in a)
y=ax
4. y=x+1 x,yεR, +2<a<+3, is well-posed
y=ax
CSE668 Sp2011 Peter Scott 07-19