CSE668 Principles
of Animate Vision Spring 2006
Systems and Control
Required
reading: [23] Maki, Nordlund and
Eklundh, Attentional scene segmentation: Integrating depth and motion from
phase, Computer Vision and Image Understanding v 78 (2000), 351-373.
We conclude our study of active and animate vision
this semester with a look at how the various skills
(motion, OR, etc.) can be pulled together into a
goal-directed system, and how the behavior of that
system can be controlled.
An important element of any active vision system is
gaze
control, that is, control
of the field of view by
manipulation of the optical axis and other extrinsic
camera model parameters, and control of the regions
of
interest (ROI) within the current field of view which
require further processing.
CSE668 Sp2006
Peter Scott 10-01
Even
without moving your eyes, you can change the
locus of attention from one region of the field of
view to another. This is called attentional
gaze
control, and is the subject
of the Maki paper. He
likens this to cognitively "shining a spotlight" on
a selected portion of the retinal image without
any change in the camera model.
For artificial active vision systems, it is essential
to be able to select those ROI's that need further
analysis effectively and quickly. The identification
of these ROI's is attentional
scene segmentation, ie.
segmenting out interesting parts of the scene for
further processing.
CSE668 Sp2006 Peter Scott 10-02
The
approach to attentional scene segmentation proposed
in this paper is a cue integration
approach. Three
visual cues which together define
the most important
ROI's for additional consideration
and processing are
computed, masks defining their locations
and extent
within the field of view determined,
and the their
intersection determined. These regions
correspond to
the ROI's for "attention."
CSE668 Sp2006 Peter Scott 10-03
Why do we need attentional segmentation?
Both in natural and in computer vision,
in general
there are two kinds of processing
of raw image
brightness data: preattentive and
attentive
processing.
Preattentive
processing: pre-processing which
occurs
automatically and uniformly over
the field of view
independent of space or time.
Attentive
processing: processing of ROI's
determined
by the vision system's attention
control mechanism to
merit additional "attention," ie.
analysis.
CSE668 Sp2006 Peter Scott 10-04
Eg: There is a parked car 100 meters ahead in the
periphery of our field of view as
we are walking in a
mall parking lot. If we are simply
doing obstacle
avoidance, a stationary distant car
does not trigger
our attention control mechanism,
we need not attend to
it. But if we are trying to find
our car in the lot,
we will need to process that information
further,
probably by foveating to it.
Like everything else in an active
vision system, the
attentive control decision process
is both task and
embodiment dependent.
CSE668 Sp2006 Peter Scott 10-05
Often the result of attentive scene
segmentation is to
identify ROI's we need to foveate
to. But another use
is to trigger reactive (stimulus-response)
rather than
cognitive (stimulus-analysis-planning-response)
behavior.
Eg: we are walking through the woods
and are about to
collide with an overhanging branch
which suddenly
appears in our FOV. We attentively
segment out the
branch and react to its radial motion
and location,
ducking away from it without foveating
to it if the
threat is immediate. Note: recall
the threat metric
1/tc = (dri/dt)/ri
and that foveation requires at least
100 ms for the
human eye.
CSE668 Sp2006 Peter Scott 10-06
Preattentive processing produces,
at each time t and
at each point (u,v) in the image
space, a vector of
values for the preattentive image
parameters at that
point. Each component can be considered
a preattentive
cue for attentive segmentation. Maki
et al select 3:
image flow, stereo disparity,
and motion detection.
There are many other preattentive
cues that might have
been selected: edges, colors, color
gradients,region
sizes, etc. They pick these because
they believe the
most important things to attend to
in in general, ie.
pre-attentively, for further processing
are nearby
objects in motion relative to the viewer.
CSE668 Sp2006 Peter Scott 10-07
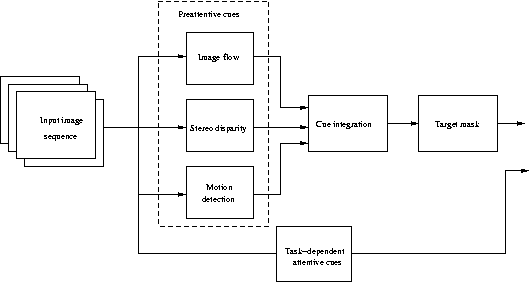
Attentional
integration of selected preattentional cues
CSE668 Sp2006 Peter Scott 10-08
Stereo disparity is the difference between where a given
point in world coordinates shows
up on the two image
planes. From stereo disparity we
can determine relative
depth. Attentional attractiveness
in this cue is low
relative depth . Maki
et al compute a dense stereo
disparity map by using a phase based
method. There are
other ways to do this, including
the sparse feature-based
and dense correlation-based methods
we discussed earlier.
CSE668 Sp2006 Peter Scott 10-09
Optical flow may be used to determine
motion in the plane
perpendicular to the optical axis.
Under orthographic
projection, optical flow is completely
insensitive to
depth motion, and for distant objects,
perspective
projection and orthographic projection
are very
similar.Maki et al choose to measure
only the 1-D
horizontal component of flow in the
plane perpendicular
to the optical axis because they
can reuse the 1-D depth
discovering disparity algorithm to
do this.
CSE668 Sp2006 Peter Scott 10-10
Motion detection is employed to segment
regions where
motion is occurring, and together
with optical flow then
used to determine the constancy of
that motion in image
regions for purposes of multi-object
segmentation.
CSE668 Sp2006 Peter Scott 10-11
Stereo disparity cue
Stereo disparity measures relative
depth. Image points
of equal disparity are at the same
depth.
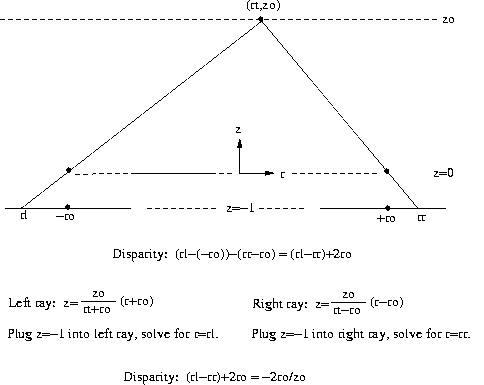
CSE668 Sp2006 Peter Scott 10-12
We see that depth is not a function
of rt, just of
stereo baseline 2ro and disparity.
So for a given
intrinsic stereo camera model, disparity
measures
relative depth.
The algorithm for determining the
disparity at image
point (x,y) used in Maki et al uses
phase difference
at a known frequency to determine
spatial difference.
1. Using a Fourier
wavelet-like kernel, compute
the magnitude
and phase V(x) of the horizontal
frequency component at the image location
x.
Repeat for left
and right images.
2. Disparity(x)
= ((ang(vl(x))-ang(vr(x)))/2pi)*T
3. T = 2pi/w,
where w ~ d/dx1 (ang(v(x))
For details see the earlier paper
by Maki et al [24].
CSE668 Sp2006 Peter Scott 10-13
Optical flow cue
Suppose we determine Vt1(x)
and Vt2(x), where t1 and t2
are successive image acquisition
times, Vt1(x) and Vt2(x)
are taken by the same camera. Then
the "disparity" measured
as above corresponds to image flow
in the horizontal
direction. In this case T corresponds
to a temporal rather
than a spatial period as before.
CSE668 Sp2006 Peter Scott 10-14
A problem with this common method
for disparity and
optical flow is that it may give
unreliable point
estimates of these two cues. They
define a confidence
parameter (certaintly map) C(x) which
is the product of
the correlation coefficient between
the two V's and their
combined strength (geometric mean
magnitude). The idea
is that x's where the V's are similar
and are strong are
reliable for using their associated
cues to determine
attentional masks.
CSE668 Sp2006 Peter Scott 10-15
Having now mapped both disparity
and optical flow
separately over the field of view,
we need to segment
out regions that are identified by
these cues as requiring
further processing. This of course
is task dependent. Maki
et al define two generic task modes,
pursuit mode and
saccade mode. Pursuit mode includes
visual servoing, shape
from motion, and docking. Saccade
mode includes visual
search, object detection, object
recognition.
CSE668 Sp2006 Peter Scott 10-16
Pursuit mode
This is also called tracking mode,
where the task is to
continue to attend to a moving target
that has already
been identified. The procedure to
create the disparity mask
Td(k) and image flow mask Tf(k)
at time k is the same:
1. Predict the change P(k) from k-1
to k in the disparity
(flow) target value based on a simple
linear update of
P(k-1).
2. Let the selected disparity (flow)
value at k be the
sum of that at k-1 plus P(k).
3. Find the nearest histogram peak
to the selected value
and define that histogram mode as
target values. Note: the
histograms are confidence-weighted.
Finally, the target mask Tp(k)is
defined as the
intersection of the disparity mask
Td(k) and image flow
mask Tf(k). This guarantees
that the target we will attend
to is both in the depth range we
predict and has the
horizontal motion we predict.
CSE668 Sp2006 Peter Scott 10-17
Saccade mode
Here the task is to identify the
region containing the
most important object that you are
not currently attending
to. The authors admit that importance
is definitely task
dependent, but stick with their assumption
that close
objects in motion are the most important
ones.
1. Eliminate the current target mask
from the images and
compute confidence-weighted disparity
histograms.
2. Back-project the high disparity
(low depth) peaks,
again eliminating current target
mask locations.
3. Intersect with motion mask.
Finally, the least-depth region in
motion is the output
saccade mode target mask.
CSE668 Sp2006 Peter Scott 10-18
Choosing between pursuit and saccade
at time k
At each time k, we may choose to
continue pursuit of the
current target in the pursuit map
Tp(k) (if there is one),
or saccade to the new one in the
saccade map Ts(k).
There are many criteria that could
be employed to
preference between these alternatives.
Some take their
input directly from the two maps,
others reach back into
the data used to compute them. For
instance:
1. Pursuit completion: pursue until
a task-completion
condition is met. For instance, object
recognition or
interception.
2. Vigilant pursuit: pursue for a
fixed period of
time, then saccade, then return to
pursuit.
3. Surveillance: saccade until all
objects with certain
characteristics within a set depth
sphere have been
detected.
CSE668 Sp2006 Peter Scott 10-19
Consistent with their depth-motion framework, Maki et al
suggest two different pursuit-saccade
decision criteria:
Depth-based: pursue until the saccade
map object is closer
than the pursuit map object.
Duration-based: pursue for a fixed
length of time.
Clearly, neither of these is sufficient.
The depth-based
criterion is not task or embodiment
dependent. We may let
an important target "get away" by
saccading to a closer
object that is for instance moving
away from us. And bad
things can happen to us during the
duration-based fixed
time that we are not alert to obstacles
and threats.
CSE668 Sp2006 Peter Scott 10-20
Example from their paper:

CSE668 Sp2006 Peter Scott 10-21
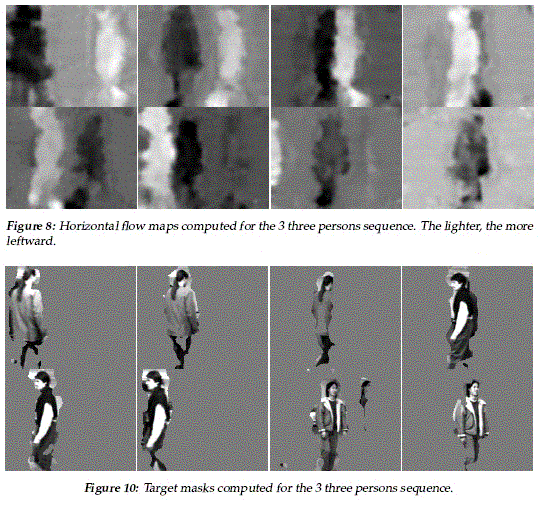
CSE668 Sp2006 Peter Scott 10-22
As a final note, lets measure the Maki et al attentive
gaze control approach against the active vision and
animate vision paradigms.
Active vision: Compute what you need as you need it
* Representations and algorithms minimal for task.
* Vision is not recovery.
* Vision is active, ie. current camera model selected
in light of current state and goals.
* Vision is embodied and goal-directed.
Animate vision: Anthropomorphic features emphasized
* Binocularity: NA
* Foveal (multiresolution) focal plane geometry
* Gaze control, both between and within eye movements
* Use fixation frames and indexical reference
CSE668 Sp2006 Peter Scott 10-23
Presentations
Begin next class April 20.
Format: 20 min Powerpoint (or equivalent)
presentation
followed by 5 min questions and answers.
Please
email
your presentation to me by 5:00PM
on the day before you
are to give your talk. I will post links
to these
files on the course home page, and
you will be able
to open them from the classroom pc
and projector.
Suggestions:
1. No more than 4-5 bullets any single
slide.
2. Illustrate with graphics wherever
possible.
3. Do at least one dry run to determine
how many
slides you are likely to cover in
20 min. Make
sure
you will have time to get to the
critical slides.
CSE668 Sp2006 Peter Scott 10-24
4. Have a core set of slides (15-25)
and a supplementary
set (0-10+) which you can cover if
you have time.
5. Your core set should include clear
statements of:
* your problem
* where it fits:
3-D/motion? passive/active?
* your basic approach
* the literature
and your relation to it
* what you have
produced to date
* what your minimal
goals for the project include
* what you will
do if you have additional time
It may include anything else as well,
but these items
are valuable in framing your project.
6. Assume audience is knowledgeable
in computer vision
but not necessarily in the exact
area of your project.
7. Oral presentation: nervousness,
which everyone feels,
tends to make you speak quickly.
Speak at a moderate pace,
be careful not to speak too quickly,
particularly if you
speak English with an accent.
8. Mention at the beginning of your
presentation if you
want questions as they occur to people,
or to hold
questions until you are done.
CSE668 Sp2006 Peter Scott 10-25