|
Jason J. Corso
|
Research Activities Overview | My research is in the fields of computer vision, medical imaging, data mining, machine learning, artificial intelligence and ontology, with various applications in study. This page lists various research snippets from my research; most snippets link to either more detailed project pages or publications. I make every effort to keep it up to date, but you should refer to the publications list for the most up-to-date listing. |
|
Supervoxel Hierarchy Flattening 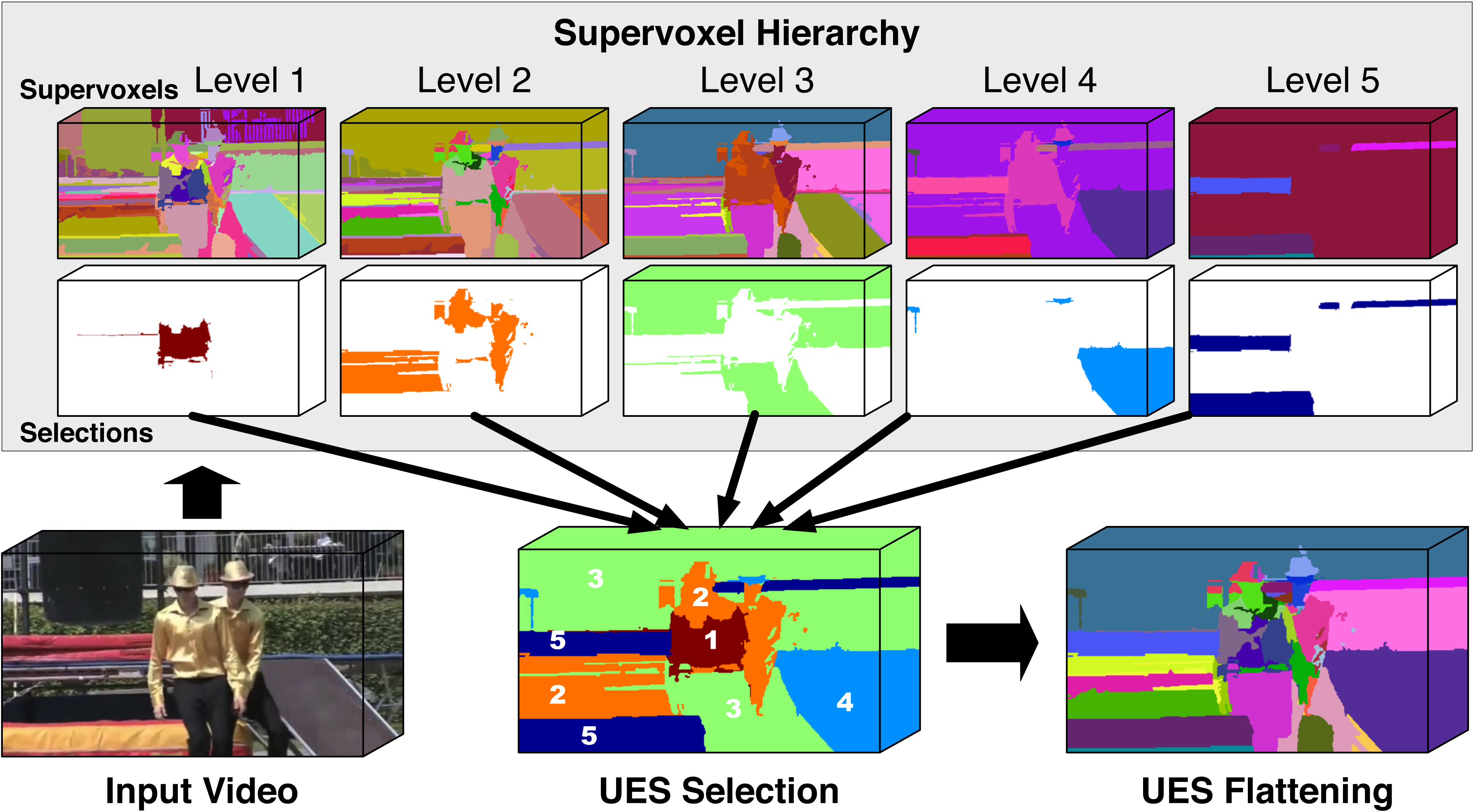 | Supervoxel hierarchies provide a rich multiscale decomposition of a given video suitable for subsequent processing in video analysis. The hierarchies are typically computed by an unsupervised process that is susceptible to under-segmentation at coarse levels and over-segmentation at fine levels, which make it a challenge to adopt the hierarchies for later use. In this paper, we propose the first method to overcome this limitation and flatten the hierarchy into a single segmentation. Our method, called the uniform entropy slice, seeks a selection of supervoxels that balances the relative level of information in the selected supervoxels based on some post hoc feature criterion such as object-ness. For example, with this criterion, in regions nearby objects, our method prefers finer supervoxels to capture the local details, but in regions away from any objects we prefer coarser supervoxels. We formulate the uniform entropy slice as a binary quadratic program and implement four different feature criteria, both unsupervised and supervised, to drive the flattening. Although we apply it only to supervoxel hierarchies in this paper, our method is generally applicable to segmentation tree hierarchies. Our experiments demonstrate both strong qualitative performance and superior quantitative performance to state of the art baselines on benchmark internet videos.
|
|
C. Xu, S. Whitt, and J. J. Corso.
Flattening supervoxel hierarchies by the uniform entropy slice.
In Proceedings of the IEEE International Conference on Computer
Vision, 2013.
[ bib |
poster |
project |
video |
.pdf ]
|
|
|
Video To Text 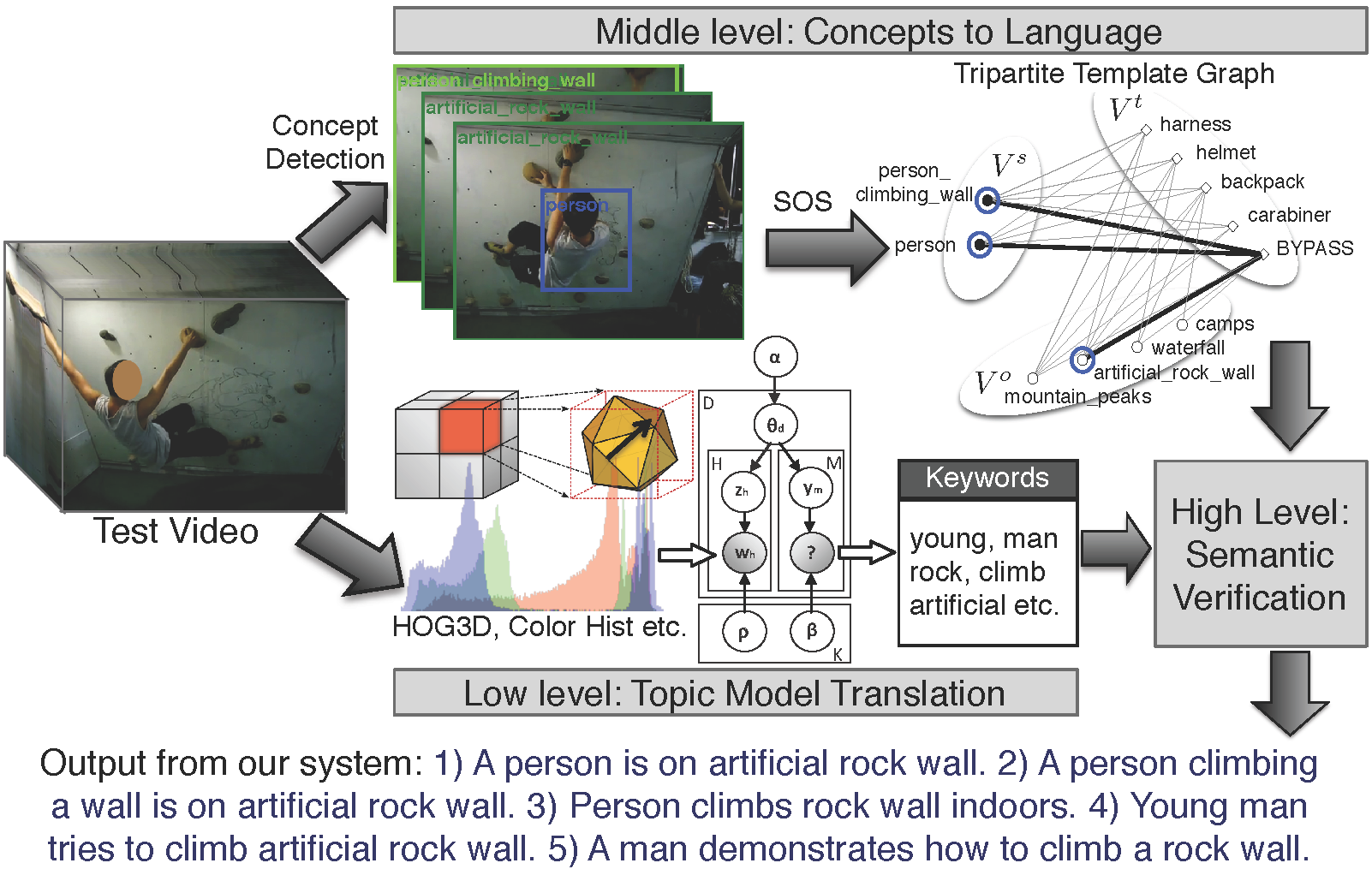 | The problem of describing images through natural language has gained importance in the computer vision community. Solutions to image description have either focused on a top-down approach of generating language through combinations of object detections and language models or bottom-up propagation of keyword tags from training images to test images through probabilistic or nearest neighbor techniques. In contrast, describing videos with natural language is a less studied problem. In this work, we combine ideas from the bottom-up and top-down approaches to image description and propose a method for video description that captures the most relevant contents of a video in a natural language description. We describe a hybrid system consisting of a low level multimodal latent topic model for initial keyword annotation, a middle level of concept detectors and a high level module to produce final lingual descriptions.
|
[1]
|
P. Das, C. Xu, R. F. Doell, and J. J. Corso.
A thousand frames in just a few words: Lingual description of videos
through latent topics and sparse object stitching.
In Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, 2013.
[ bib |
poster |
data |
.pdf ]
|
|
[2]
|
P. Das, R. K. Srihari, and J. J. Corso.
Translating related words to videos and back through latent topics.
In Proceedings of Sixth ACM International Conference on Web
Search and Data Mining, 2013.
[ bib |
.pdf ]
|
|
|
Streaming Hierarchical Video Segmentation 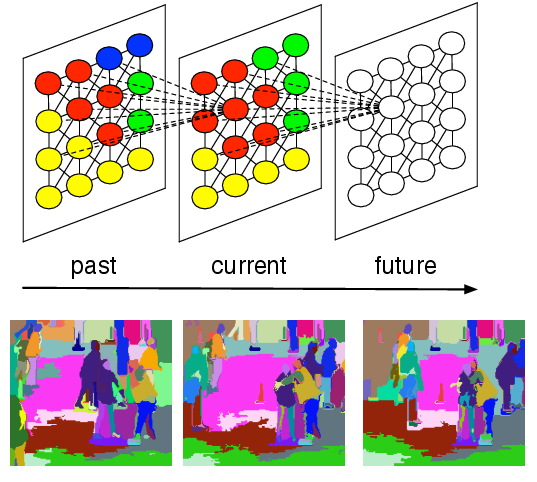 | The use of video segmentation as an early processing step in video analysis lags behind the use of image segmentation for image analysis, despite many available video segmentation methods. A major reason for this lag is simply that videos are an order of magnitude bigger than images; yet most methods require all voxels in the video to be loaded into memory, which is clearly prohibitive for even medium length videos. We address this limitation by proposing an approximation framework for streaming hierarchical video segmentation motivated by data stream algorithms: each video frame is processed only once and does not change the segmentation of previous frames. We implement the graph-based hierarchical segmentation method within our streaming framework; our method is the first streaming hierarchical video segmentation method proposed.
|
|
C. Xu, C. Xiong, and J. J. Corso.
Streaming hierarchical video segmentation.
In Proceedings of European Conference on Computer Vision, 2012.
[ bib |
code |
project |
.pdf ]
|
StreamGBH is included as part of LIBSVX |
|
Random Forest Distance 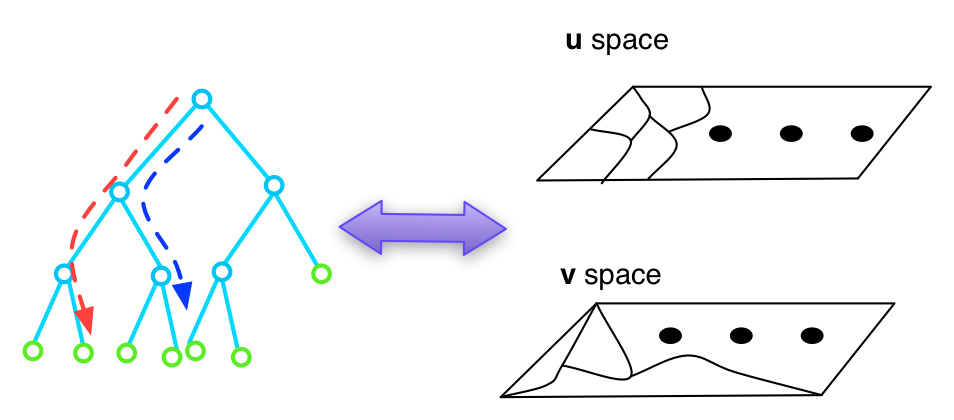 | Metric learning makes it plausible to learn semantically meaningful distances for complex distributions of data using label or pairwise constraint information. However, to date, most metric learning methods are based on a single Mahalanobis metric, which cannot handle heterogeneous data well. Those that learn multiple metrics throughout the feature space have demonstrated superior accuracy, but at a severe cost to computational efficiency. Here, we adopt a new angle on the metric learning problem and learn a single metric that is able to implicitly adapt its distance function throughout the feature space. This metric adaptation is accomplished by using a random forest-based classifier to underpin the distance function and incorporate both absolute pairwise position and standard relative position into the representation. We have implemented and tested our method against state of the art global and multi-metric methods on a variety of data sets. Overall, the proposed method outperforms both types of method in terms of accuracy (consistently ranked first) and is an order of magnitude faster than state of the art multi-metric methods (16x faster in the worst case).
|
|
C. Xiong, D. Johnson, R. Xu, and J. J. Corso.
Random forests for metric learning with implicit pairwise position
dependence.
In Proceedings of ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining, 2012.
[ bib |
slides |
code |
.pdf ]
|
|
|
Action Bank 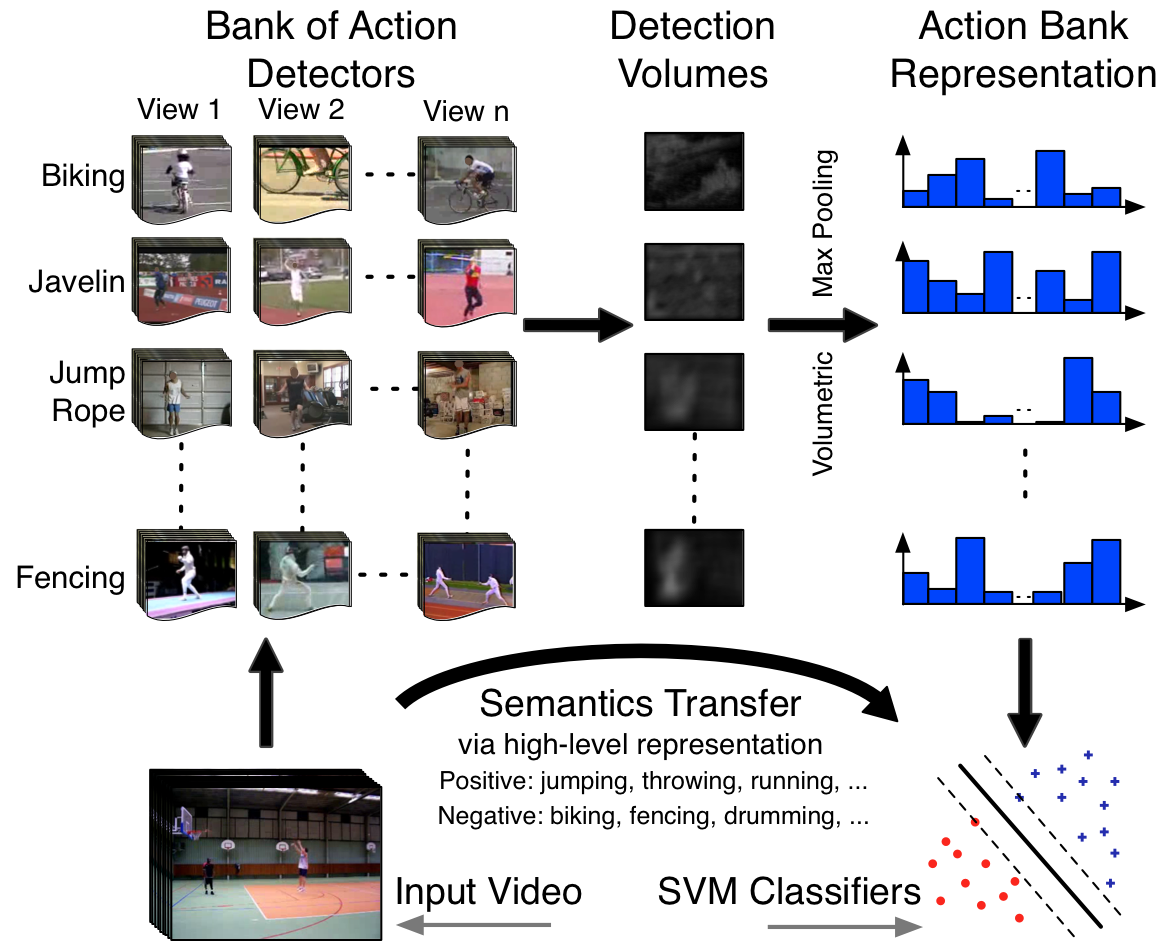 | Activity recognition in video is dominated by low- and mid-level features, and while demonstrably capable, by nature, these features carry little semantic meaning. Inspired by the recent object bank approach to image representation, we present Action Bank, a new high-level representation of video. Action bank is comprised of many individual action detectors sampled broadly in semantic space as well as viewpoint space. Our representation is constructed to be semantically rich and even when paired with simple linear SVM classifiers is capable of highly discriminative performance. We have tested action bank on four major activity recognition benchmarks. In all cases, our performance is significantly better than the state of the art, namely 98.2% on KTH (better by 3.3%), 95.0% on UCF Sports (better by 3.7%), 76.4% on UCF50 (baseline is 47.9%), and 38.0% on HMDB51 (baseline is 23.2%). Furthermore, when we analyze the classifiers, we find strong transfer of semantics from the constituent action detectors to the bank classifier.
|
|
S. Sadanand and J. J. Corso.
Action bank: A high-level representation of activity in video.
In Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, 2012.
[ bib |
code |
project |
.pdf ]
|
More information, data and code are available at the project page. |
|
Dynamic Pose for Human Activity Recognition  | Recent work in human activity recognition has focused on bottom-up approaches that rely on spatiotemporal features, both dense and sparse. In contrast, articulated motion, which naturally incorporates explicit human action information, has not been heavily studied; a fact likely due to the inherent challenge in modeling and inferring articulated human motion from video. However, recent developments in data-driven human pose estimation have made it plausible. In this work, we extend these developments with a new middle-level representation called dynamic pose that couples the local motion information directly and in- dependently with human skeletal pose, and present an appropriate distance function on the dynamic poses. We demonstrate the representative power of dynamic pose over raw skeletal pose in an activity recognition setting, using simple codebook matching and support vector machines as the classifier. Our results conclusively demonstrate that dynamic pose is a more powerful representation of human action than skeletal pose.
|
|
R. Xu, P. Agarwal, S. Kumar, V. N. Krovi, and J. J. Corso.
Combining skeletal pose with local motion for human activity
recognition.
In Proceedings of VII Conference on Articulated Motion and
Deformable Objects, 2012.
[ bib |
slides |
.pdf ]
|
|
|
Efficient Max-Margin Metric Learning 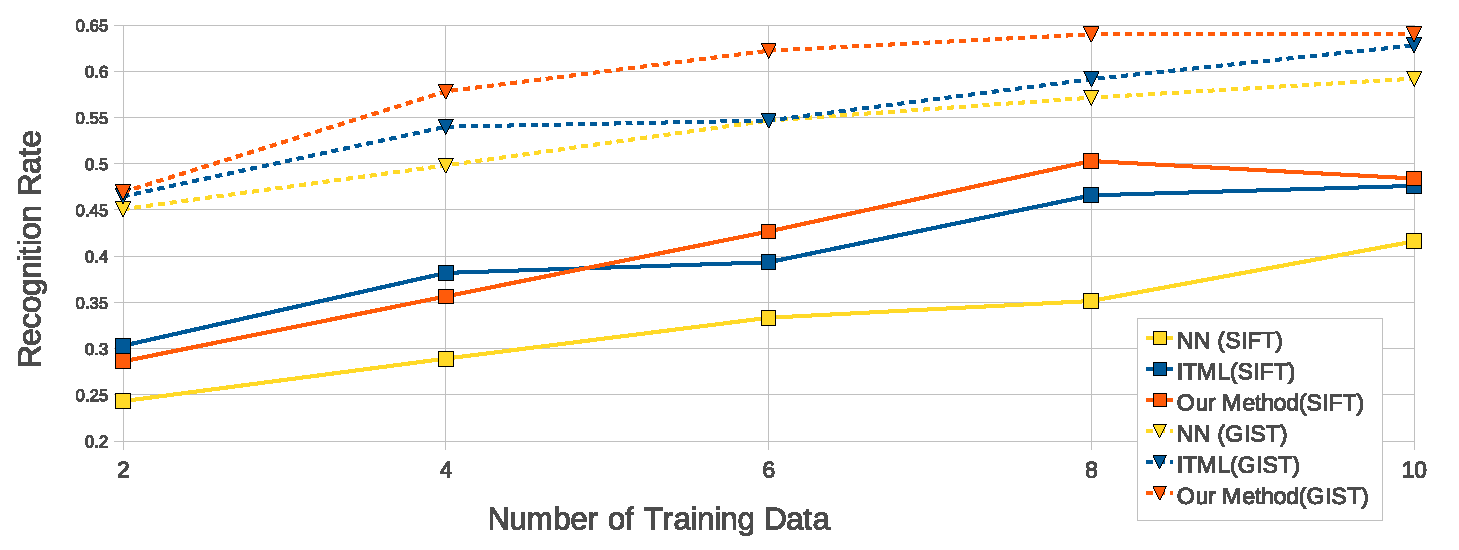 | Efficient learning of an appropriate distance metric is an increasingly important problem in machine learning. However, current methods are limited by scalability issues or are unsuited to use with general similarity/dissimilarity constraints. In this work, we propose an efficient metric learning method based on the max-margin framework with pairwise constraints that has strong generalization guarantee. First, we reformulate the max-margin metric learning problem as a structured support vector machine which we can optimize in linear time via a cutting-plane method. Second, we propose an approximation method for our kernelized extension based on match pursuit algorithm that allows linear-time training. We find our method to be comparable to or better than state of the art metric learning techniques at a number of machine learning and computer vision classification tasks.
|
|
C. Xiong, D. Johnson, and J. J. Corso.
Efficient max-margin metric learning.
In Proceedings of European Conference on Data Mining, 2012.
Winner of Best Paper Award at ECDM 2012.
[ bib |
.pdf ]
|
|
|
Spectral Active Clustering 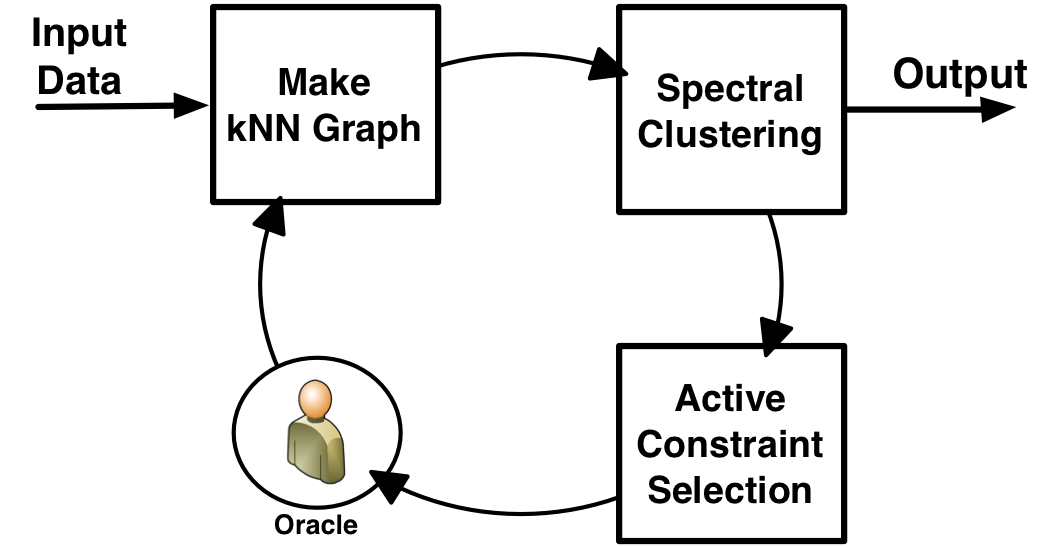 | Spectral clustering is widely used in data mining, machine learning and pattern recognition. There have been some recent developments in adding pairwise constraints as side information to enforce top-down structure into the clustering results. However, most of these algorithms are "passive" in the sense that the side information is provided beforehand. In this work, we present a spectral active clustering method that actively select pairwise constraints based on a novel notion of node uncertainty rather than pair uncertainty. In our approach, the constraints are used to drive a purification process on the k-nearest neighbor graph---edges are removed from the graph based on the constraints---that ultimately leads to an improved, constraint-satisfied clustering. We have evaluated our framework on three datasets (UCI, gene and image sets) in the context of baseline and state of the art methods and find the proposed algorithm to be superiorly effective.
|
|
C. Xiong, D. Johnson, and J. J. Corso.
Spectral active clustering via purification of the k-nearest
neighbor graph.
In Proceedings of European Conference on Data Mining, 2012.
[ bib |
.pdf ]
|
This work is part of our ACE project. |
|
Parts-based Model of the Full Scene 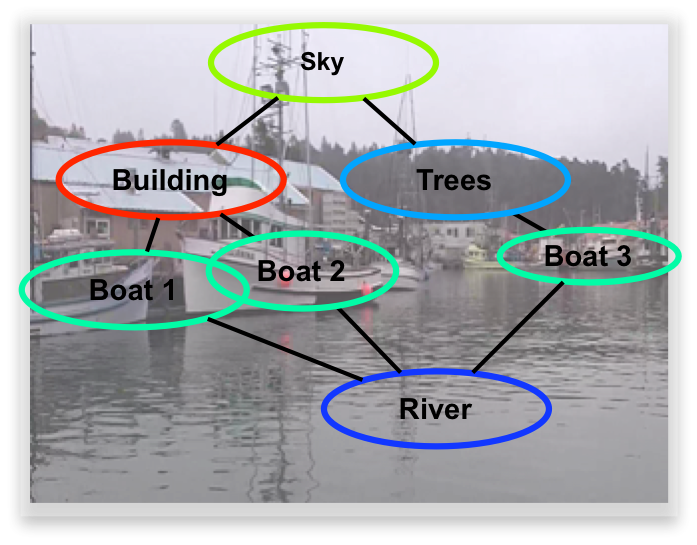 | Scene understanding remains a significant challenge in the computer vision community. The visual psychophysics literature has demonstrated the importance of interdependence among parts of the scene. Yet, the majority of methods in scene understanding remain local. Pictorial structures have arisen as a fundamental parts-based model for some vision problems, such as articulated object detection. However, the form of classical pictorial structures limits their applicability for global problems, such as semantic pixel labeling. In this work, we propose an extension of the pictorial structures approach, called pixel-support parts-sparse pictorial structures, or PS3, to overcome this limitation. Our model extends the classical form in two ways: first, it defines parts directly based on pixel-support rather than in a parametric form, and second, it specifies a space of plausible parts-based scene models and permits one to be used for inference on any given image. PS3 makes strides toward unifying object-level and pixel-level modeling of scene elements. We have thus far implemented the first half of our model and rely upon external knowledge to provide an initial graph structure for a given image.
|
|
J. J. Corso.
Toward parts-based scene understanding with pixel-support
parts-sparse pictorial structures.
Pattern Recognition Letters: Special Issue on Scene
Understanding and Behavior Analysis, 34(7):762-769, 2013.
Early version appears as arXiv.org tech report 1108.4079v1.
[ bib |
.pdf ]
|
More information about our earlier work in semantic region labeling is available here. |
|
Evaluation of Supervoxels for Early Video Processing 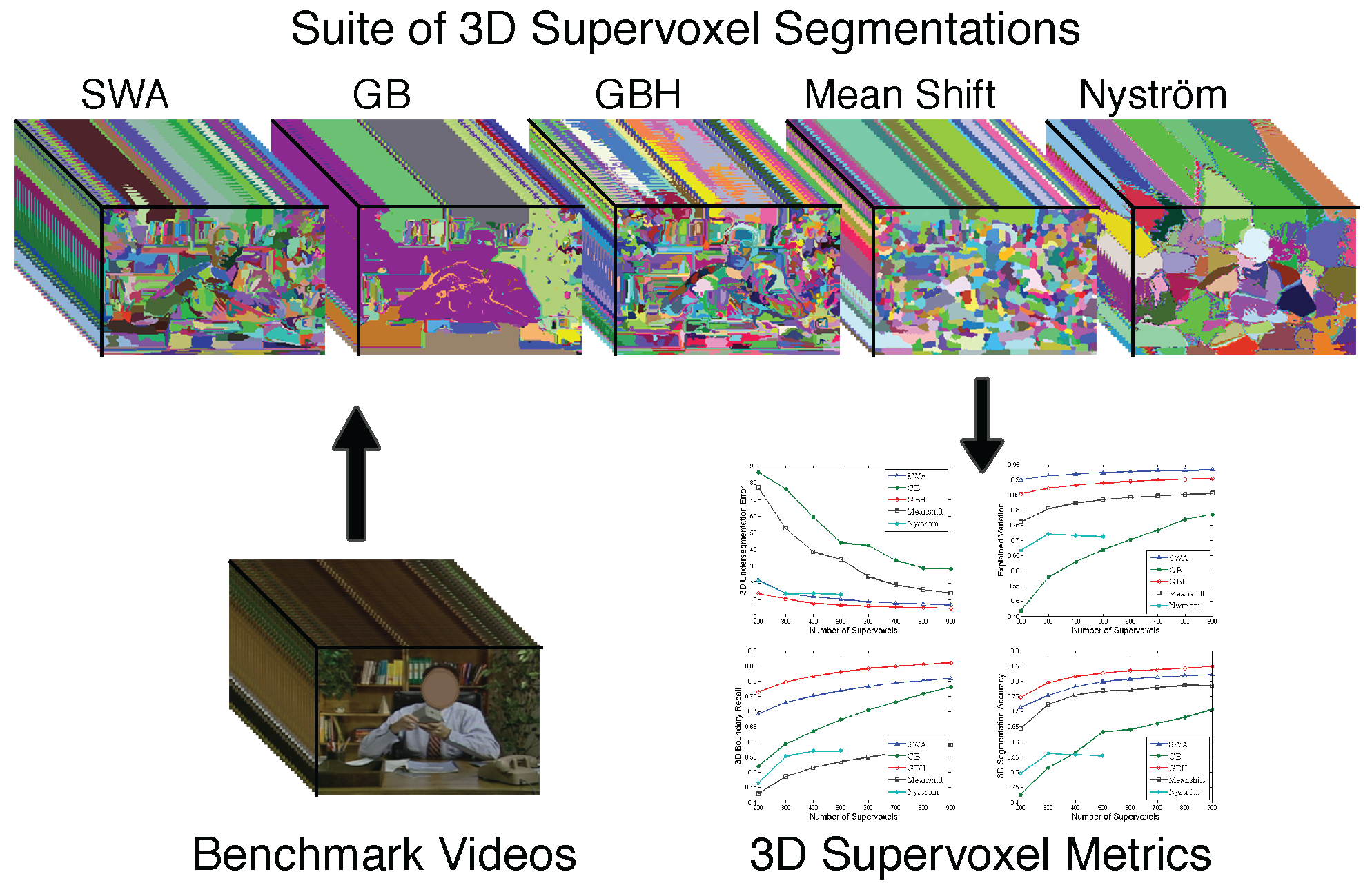 | Supervoxel segmentation has strong potential to be incorporated into early video analysis as superpixel segmentation has in image analysis. However, there are many plausible supervoxel methods and little understanding as to when and where each is most appropriate. Indeed, we are not aware of a single comparative study on supervoxel segmentation. To that end, we study five supervoxel algorithms in the context of what we consider to be a good supervoxel: namely, spatiotemporal uniformity, object/region boundary detection, region compression and parsimony. For the evaluation we propose a comprehensive suite of 3D volumetric quality metrics to measure these desirable supervoxel characteristics. Our findings have led us to conclusive evidence that the hierarchical graph-based and segmentation by weighted aggregation methods perform best and almost equally-well.
|
|
C. Xu and J. J. Corso.
Evaluation of super-voxel methods for early video processing.
In Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, 2012.
[ bib |
code |
project |
.pdf ]
|
All supervoxel methods are included as part of LIBSVX |
|
Two-Layer Probabilistic Model Jointly on Pixel and Object Features 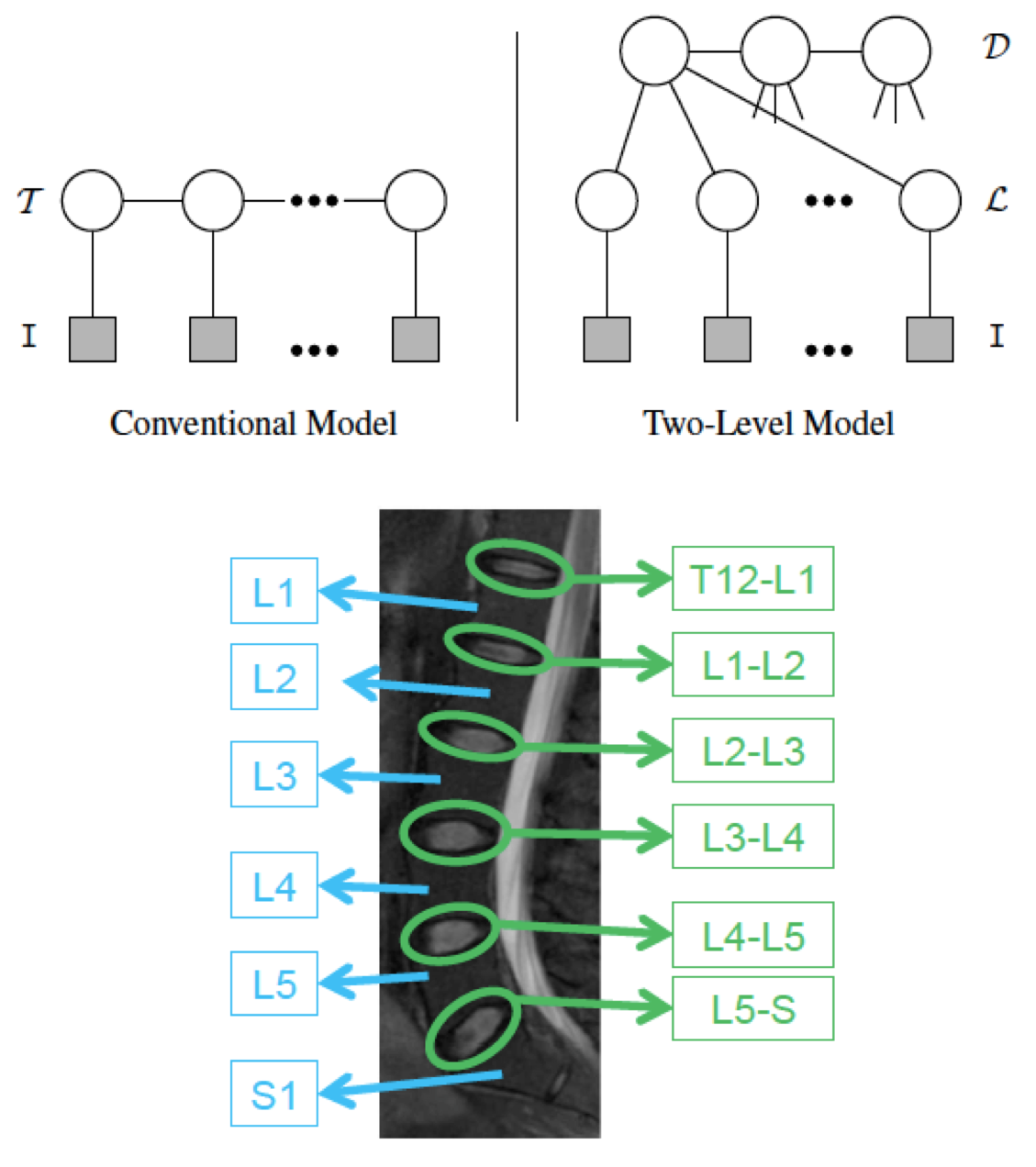 | We have developed a two-level probabilistic model for jointly localizing and labeling lumbar discs Whereas conventional labeling approaches (e.g., our approach to brain tumor above) define all models at the pixel level, our model integrates both pixel-level information, such as appearance, and object-level information, such as relative location and shape. Utilizing both levels of information adds robustness to the ambiguous disc intensity signature and high structure variation. Yet, we are able to do efficient (and convergent) localization and labeling with generalized expectation-maximization. We have presented accurate results, about 89% accuracy on 105 normal and abnormal cases (96% when using normal alone and 87% when using abnormal alone). More information.
|
|
R. S. Alomari, J. J. Corso, and V. Chaudhary.
Labeling of lumbar discs using both pixel- and object-level features
with a two-level probabilistic model.
IEEE Transactions on Medical Imaging, 30(1):1-10, 2011.
[ bib |
.pdf ]
|
|
|
Generalized Image Understanding 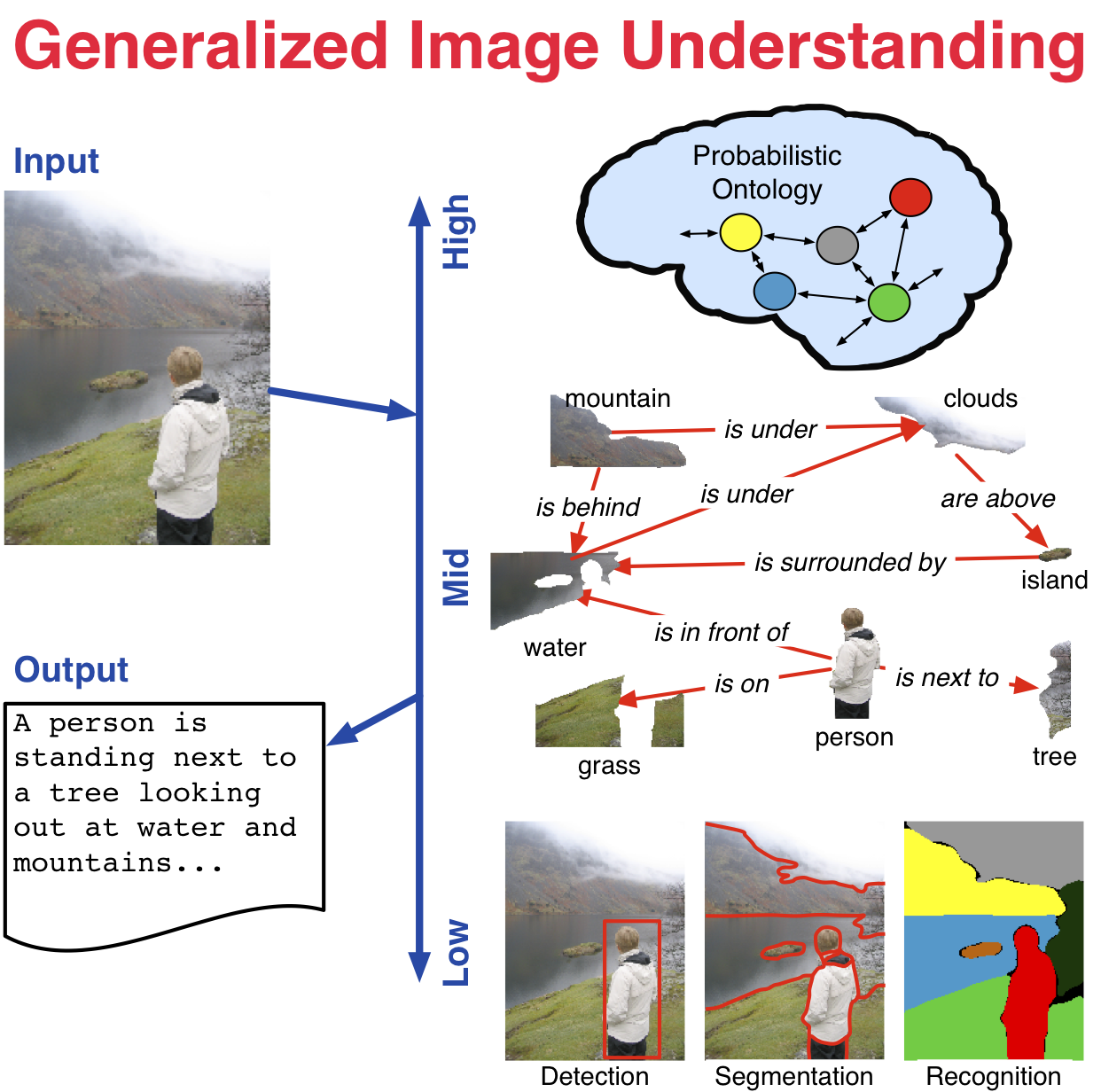 | NSF CAREER project is underway. From representation to learning to inference, effective use of high-level semantic knowledge in computer vision remains a challenge in bridging the signal-symbol gap. This research investigates the role of semantics in visual inference through the generalized image understanding problem: to automatically detect, localize, segment, and recognize the core high-level elements and how they interact in an image, and provide a parsimonious semantic description of the image. Specifically, this research examines a unified methodology that integrates low- (e.g., pixels and features), mid- (e.g. latent structure), and high-level (e.g., semantics) elements for visual inference. Adaptive graph hierarchies induced directly from the images provide the core mathematical representation. A statistical interpretation of affinities between neighboring pixels and regions in the image drives this induction. Latent elements and structure are captured with multilevel Markov networks. A probabilistic ontology represents the core knowledge and uncertainty of the inferred structure and guides the ultimate semantic interpretation of the image. At each level, rigorous methods from computer science and statistics are connected to and combined with formal semantic methods from philosophy. |
|
Graph-Shifts: Greedy Hierarchical Energy Minimization 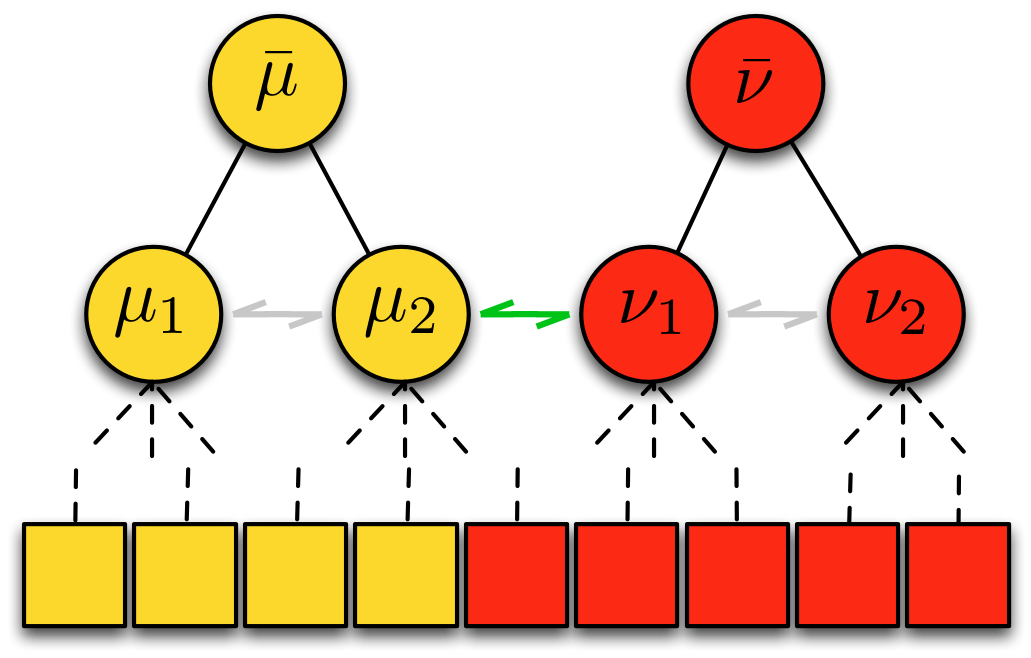 | Graph-Shifts is an energy minimization algorithm that manipulates a dynamic hierarchical decomposition of the data to rapidly and robustly minimize an energy function. It is a steepest descent minimizer that explores a non-local search space during minimization. A dynamic hierarchical representation makes exploration of this large search space plausible, and it facilitates both large jumps in the energy space analogous to combined split-and-merge operations as well as small jumps analogous to PDE-like moves. We use a deterministic approach to quickly choose the optimal move at each iteration. It has been applied in 2D and 3D joint image segmentation and classification in medical images, as depicted below for the segmentation of subcortical brain structures, and natural images as depicted at the semantic image labeling page. Graph-shifts typically converges orders of magnitude faster than conventional minimization algorithms, like PDE-based methods, and has been shown to be very robust to initialization.
|
|
J. J. Corso, A. Yuille, and Z. Tu.
Graph-Shifts: Natural Image Labeling by Dynamic Hierarchical
Computing.
In Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, 2008.
[ bib |
code |
project |
.pdf ]
|
More information and code. |
|
Multilevel Segmentation with Bayesian Affinities  | Automatic segmentation is a difficult problem: it is under-constrained, precise physical models are generally not yet known, and the data presents high intra-class variance. In this research, we study methods for automatic segmentation of image data that strive to leverage the efficiency of bottom-up algorithms with the power of top-down models. The work takes one step toward unifying two state-of-the-art image segmentation approaches: graph affinity-based and generative model-based segmentation. Specifically, the main contribution of the work is a mathematical formulation for incorporating soft model assignments into the calculation of affinities, which are traditionally model free. This Bayesian model-aware affinity measurement has been integrated into the multilevel Segmentation by Weighted Aggregation algorithm. As a byproduct of the integrated Bayesian model classification, each node in the graph hierarchy is assigned a most likely model class according to a set of learned model classes. The technique has been applied to the task of detecting and segmenting brain tumor and edema, subcortical brain structures and multiple sclerosis lesions in multichannel magnetic resonance image volumes. More information. |
|
A Data Set for Video Label Propagation |
Listing of Older Research Activities |
Acknowledgements of Support | We gratefully acknowledge funding support from the following agencies and programs. |
|
|