|
Jason J. Corso
|
Snippet Topic: Video Understanding
Supervoxel Hierarchy Flattening 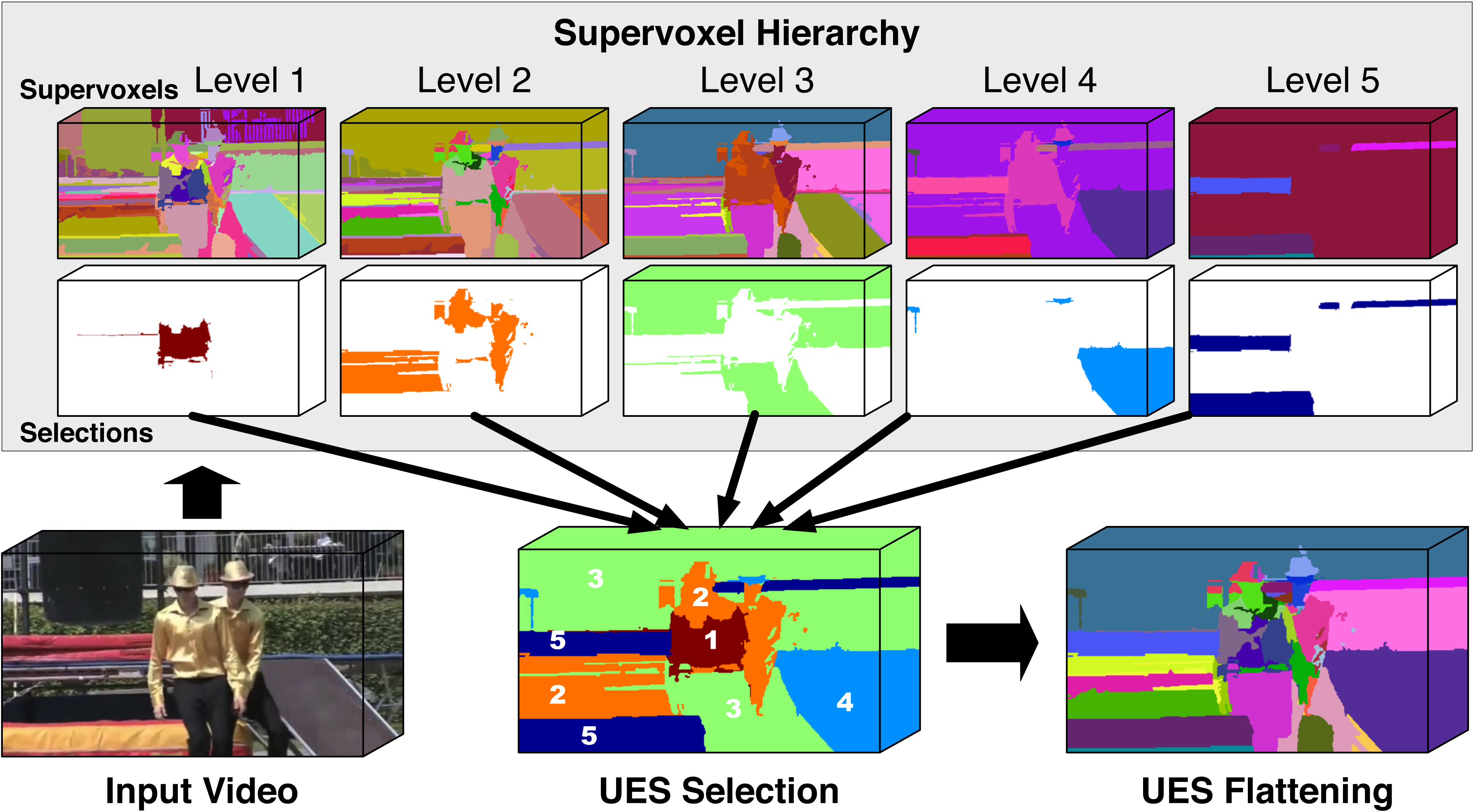 | Supervoxel hierarchies provide a rich multiscale decomposition of a given video suitable for subsequent processing in video analysis. The hierarchies are typically computed by an unsupervised process that is susceptible to under-segmentation at coarse levels and over-segmentation at fine levels, which make it a challenge to adopt the hierarchies for later use. In this paper, we propose the first method to overcome this limitation and flatten the hierarchy into a single segmentation. Our method, called the uniform entropy slice, seeks a selection of supervoxels that balances the relative level of information in the selected supervoxels based on some post hoc feature criterion such as object-ness. For example, with this criterion, in regions nearby objects, our method prefers finer supervoxels to capture the local details, but in regions away from any objects we prefer coarser supervoxels. We formulate the uniform entropy slice as a binary quadratic program and implement four different feature criteria, both unsupervised and supervised, to drive the flattening. Although we apply it only to supervoxel hierarchies in this paper, our method is generally applicable to segmentation tree hierarchies. Our experiments demonstrate both strong qualitative performance and superior quantitative performance to state of the art baselines on benchmark internet videos.
|
|
C. Xu, S. Whitt, and J. J. Corso.
Flattening supervoxel hierarchies by the uniform entropy slice.
In Proceedings of the IEEE International Conference on Computer
Vision, 2013.
[ bib |
poster |
project |
video |
.pdf ]
|
|
|
Video To Text 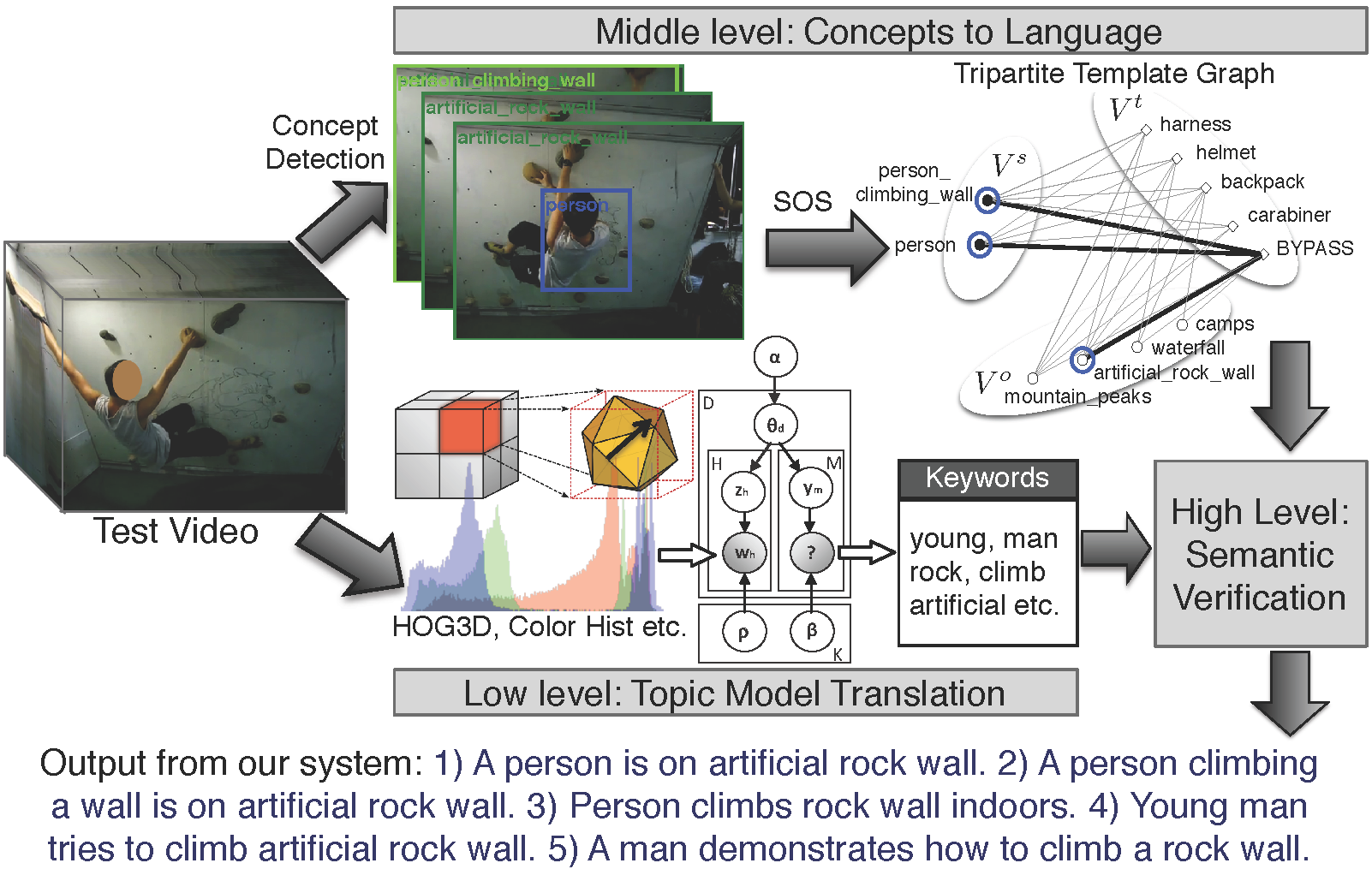 | The problem of describing images through natural language has gained importance in the computer vision community. Solutions to image description have either focused on a top-down approach of generating language through combinations of object detections and language models or bottom-up propagation of keyword tags from training images to test images through probabilistic or nearest neighbor techniques. In contrast, describing videos with natural language is a less studied problem. In this work, we combine ideas from the bottom-up and top-down approaches to image description and propose a method for video description that captures the most relevant contents of a video in a natural language description. We describe a hybrid system consisting of a low level multimodal latent topic model for initial keyword annotation, a middle level of concept detectors and a high level module to produce final lingual descriptions.
|
[1]
|
P. Das, C. Xu, R. F. Doell, and J. J. Corso.
A thousand frames in just a few words: Lingual description of videos
through latent topics and sparse object stitching.
In Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, 2013.
[ bib |
poster |
data |
.pdf ]
|
|
[2]
|
P. Das, R. K. Srihari, and J. J. Corso.
Translating related words to videos and back through latent topics.
In Proceedings of Sixth ACM International Conference on Web
Search and Data Mining, 2013.
[ bib |
.pdf ]
|
|
|
Streaming Hierarchical Video Segmentation 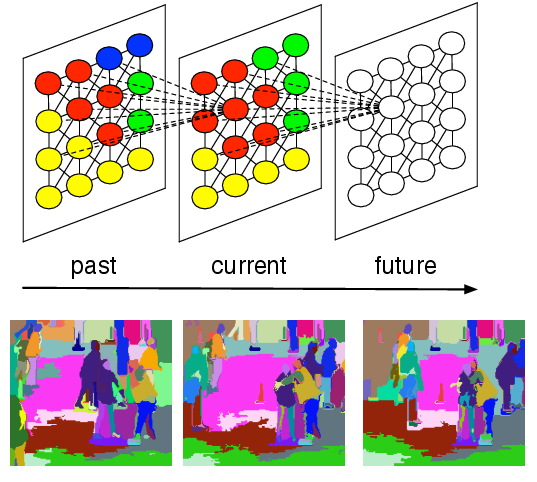 | The use of video segmentation as an early processing step in video analysis lags behind the use of image segmentation for image analysis, despite many available video segmentation methods. A major reason for this lag is simply that videos are an order of magnitude bigger than images; yet most methods require all voxels in the video to be loaded into memory, which is clearly prohibitive for even medium length videos. We address this limitation by proposing an approximation framework for streaming hierarchical video segmentation motivated by data stream algorithms: each video frame is processed only once and does not change the segmentation of previous frames. We implement the graph-based hierarchical segmentation method within our streaming framework; our method is the first streaming hierarchical video segmentation method proposed.
|
|
C. Xu, C. Xiong, and J. J. Corso.
Streaming hierarchical video segmentation.
In Proceedings of European Conference on Computer Vision, 2012.
[ bib |
code |
project |
.pdf ]
|
StreamGBH is included as part of LIBSVX |
|
Action Bank 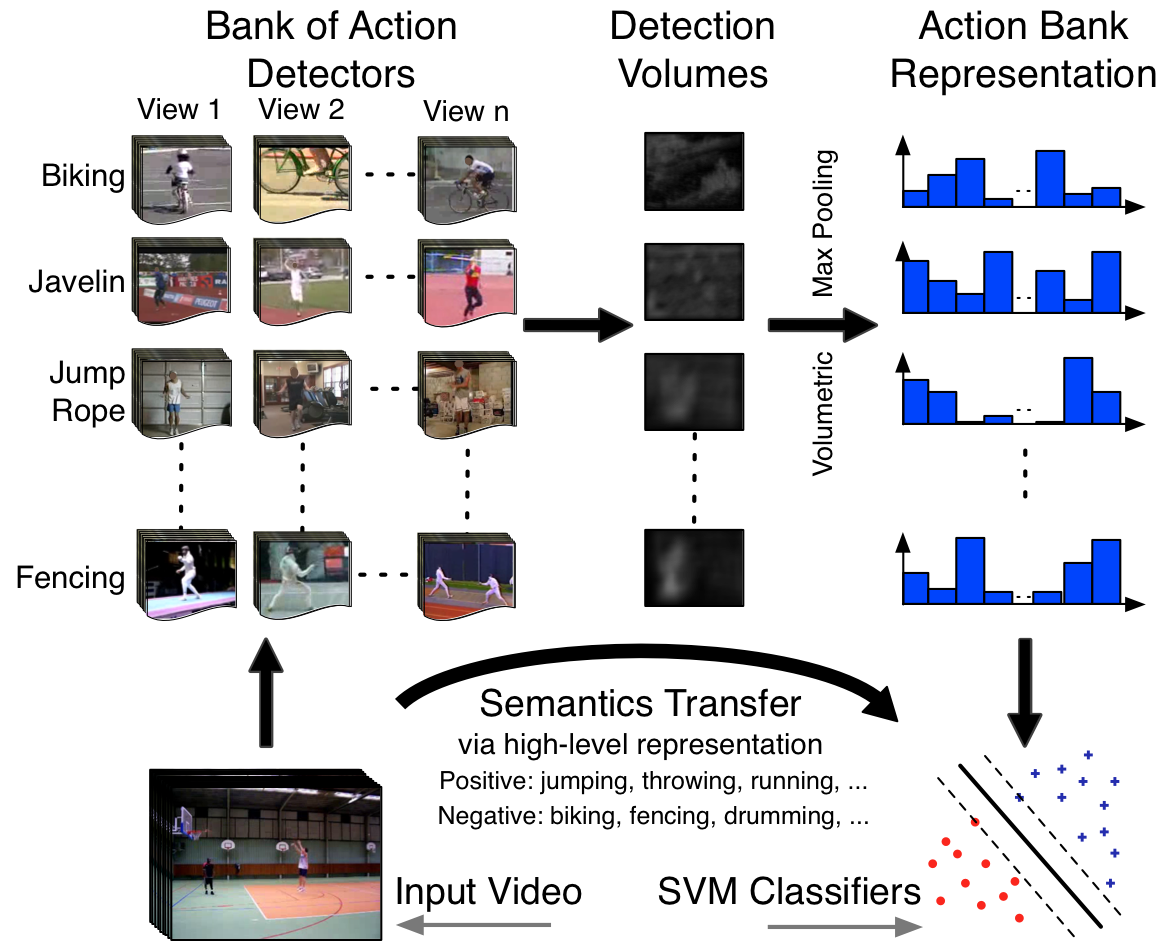 | Activity recognition in video is dominated by low- and mid-level features, and while demonstrably capable, by nature, these features carry little semantic meaning. Inspired by the recent object bank approach to image representation, we present Action Bank, a new high-level representation of video. Action bank is comprised of many individual action detectors sampled broadly in semantic space as well as viewpoint space. Our representation is constructed to be semantically rich and even when paired with simple linear SVM classifiers is capable of highly discriminative performance. We have tested action bank on four major activity recognition benchmarks. In all cases, our performance is significantly better than the state of the art, namely 98.2% on KTH (better by 3.3%), 95.0% on UCF Sports (better by 3.7%), 76.4% on UCF50 (baseline is 47.9%), and 38.0% on HMDB51 (baseline is 23.2%). Furthermore, when we analyze the classifiers, we find strong transfer of semantics from the constituent action detectors to the bank classifier.
|
|
S. Sadanand and J. J. Corso.
Action bank: A high-level representation of activity in video.
In Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, 2012.
[ bib |
code |
project |
.pdf ]
|
More information, data and code are available at the project page. |
|
Dynamic Pose for Human Activity Recognition  | Recent work in human activity recognition has focused on bottom-up approaches that rely on spatiotemporal features, both dense and sparse. In contrast, articulated motion, which naturally incorporates explicit human action information, has not been heavily studied; a fact likely due to the inherent challenge in modeling and inferring articulated human motion from video. However, recent developments in data-driven human pose estimation have made it plausible. In this work, we extend these developments with a new middle-level representation called dynamic pose that couples the local motion information directly and in- dependently with human skeletal pose, and present an appropriate distance function on the dynamic poses. We demonstrate the representative power of dynamic pose over raw skeletal pose in an activity recognition setting, using simple codebook matching and support vector machines as the classifier. Our results conclusively demonstrate that dynamic pose is a more powerful representation of human action than skeletal pose.
|
|
R. Xu, P. Agarwal, S. Kumar, V. N. Krovi, and J. J. Corso.
Combining skeletal pose with local motion for human activity
recognition.
In Proceedings of VII Conference on Articulated Motion and
Deformable Objects, 2012.
[ bib |
slides |
.pdf ]
|
|
|
Evaluation of Supervoxels for Early Video Processing 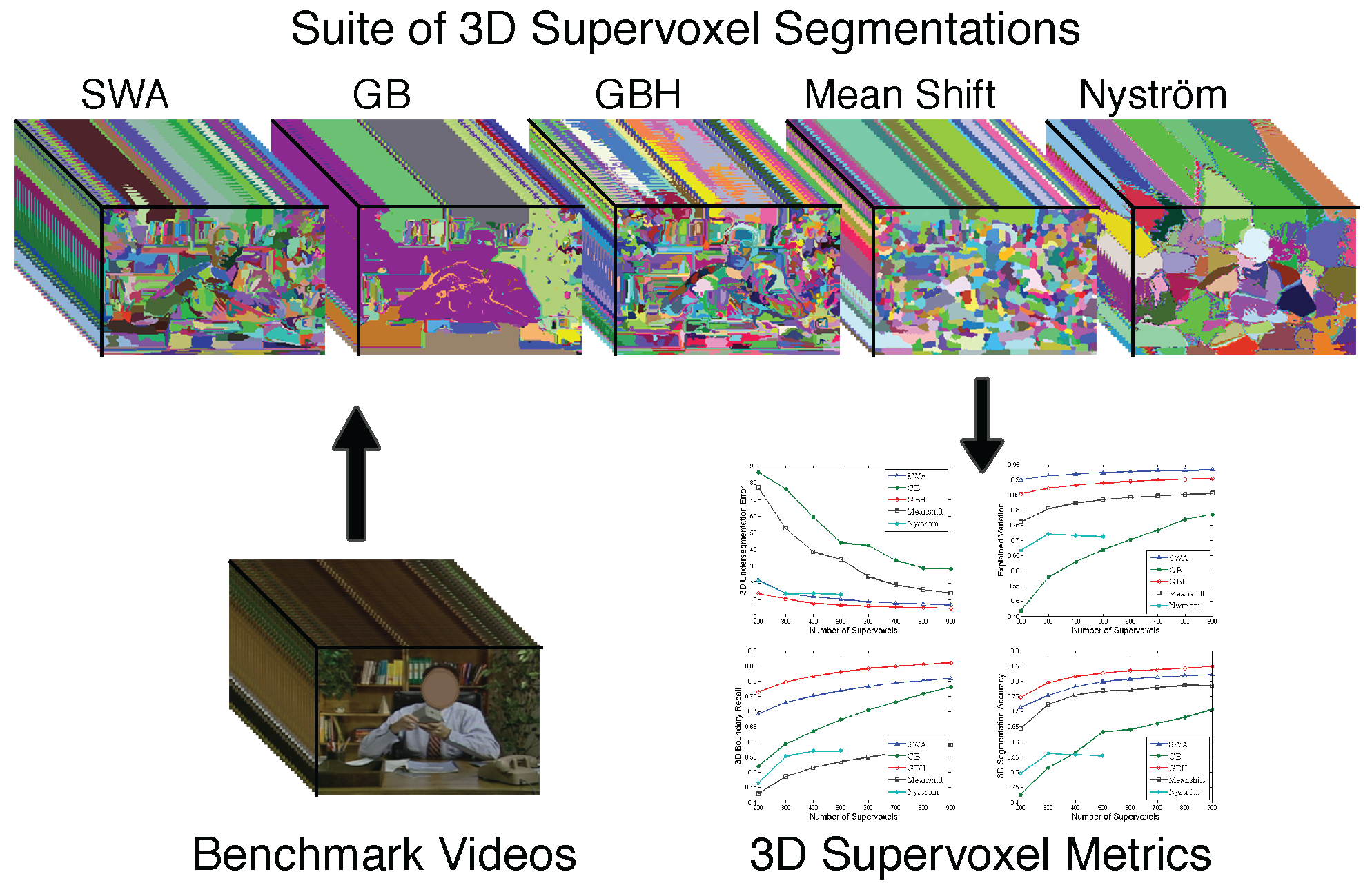 | Supervoxel segmentation has strong potential to be incorporated into early video analysis as superpixel segmentation has in image analysis. However, there are many plausible supervoxel methods and little understanding as to when and where each is most appropriate. Indeed, we are not aware of a single comparative study on supervoxel segmentation. To that end, we study five supervoxel algorithms in the context of what we consider to be a good supervoxel: namely, spatiotemporal uniformity, object/region boundary detection, region compression and parsimony. For the evaluation we propose a comprehensive suite of 3D volumetric quality metrics to measure these desirable supervoxel characteristics. Our findings have led us to conclusive evidence that the hierarchical graph-based and segmentation by weighted aggregation methods perform best and almost equally-well.
|
|
C. Xu and J. J. Corso.
Evaluation of super-voxel methods for early video processing.
In Proceedings of IEEE Conference on Computer Vision and
Pattern Recognition, 2012.
[ bib |
code |
project |
.pdf ]
|
All supervoxel methods are included as part of LIBSVX |
|
A Data Set for Video Label Propagation |
|

