8. Passive Motion Analysis
- Reading: Trucco and Verri, "Introductory Techniques for 3-D Computer Vision",
- Chapter 8
We continue the study of passive vision for 3-D and motion recovery by considering 3-D computer vision problems in which there is relative motion between the camera (or cameras) and objects in the scene, and multiple images with at least some overlap of the fields of view.
- Eg: Sequence of video frames taken with fixed camera model, several objects moving in the scene.
- Eg: Capture an image of a still object, change the extrinsic camera model, take a second image.
The relative motion might be due to either egomotion or independent object motion.
Note that stereo imaging can be considered a special case of motion analysis for still objects (take one image, move camera, take second image).
Motion analysis is important for two quite different reasons:
-
In both natural and computer vision, objects we need to recognize and
characterize are often in motion, so we need to be able to do shape modelling
and OR in spite of motion.
- Eg: Read a street sign as we drive past it quickly.
- Eg: A juggler needs to catch a tumbling bowling pin by its neck.
-
Visual cues due to motion can be very helpful deriving important information
about the scene semantics, the meaning of the scene. There are things we
can work out because of motion.
- Eg: We walk around a statue to appreciate its full 3-D shape.
- Eg: Random dot sequence imagery.

- Eg: Time-to-impact can be computed from the rate of change of the size of an object.

Assume black dot is moving with velocity v parallel to the z axis and \(z(t_0)=D_0\). We want to determine the time-to-impact t'(t) such that z(t'(t))=0. Clearly \(t'=(D_0-v t)/v\), but we only know l(t), the image location of the dot.
But
\(l(t) = L f/[f+(D_0-v t)] = L f (f+D_0-v t)^{-1}\)
\(dl/dt = -L f (f+D_0-v t)^{-2} (-v)\)
\(= l(t) (v/[f+D_0-v t])\)
For \(D_0>>f\)
\(l(t)/(dl/dt) = (D_0-v t)/v = t'(t)\)
So just from the image location at any time t, and its rate of change at that time, we can determine the time to impact t' (in practical situations, estimate t'). There is of course no way to get t' from a still.
The basic problem of motion analysis is to derive scene semantics from high frame rate image sequences. That is, for much of this work we will assume the displacement of a typical object point between successive images is small.
The assumption of incremental displacement makes the correspondence problem much easier than in stereo, where the disparity can be large.
Using the assumption of incremental displacement, we can make the approximation that the brightness value of a typical image point does not change between successive frames. Thus the correspondence problem becomes that of estimating the apparent motion of the image brightness distribution, what is called optical flow.
Optical flow
Let E(x,y,t) represent the image brightness at point (x,y) in image coordinates at time t. An image point (x,y) will appear at the point x+dx, y+dy, at time t+dt if it has velocity vector, which we refer to as the motion field vector v
\(v(x,y,t) = [∂x/∂t, ∂y/∂t]^T\)
Over an infinitesimal increment of time and space we assume the brightness of that same object point will not change, ie. E(x+dx,y+dy,t+dt) = E(x,y,t), or dE(x,y,t)=0.

But
\(dE = ∂E/∂x \, dx + ∂E/∂y \, dy + ∂E/∂t \, dt\)
and for
\(dx = ∂x/∂t \, dt, \; dy = ∂y/∂t \, dt\)
where
\([∂x/∂t, ∂y/∂t]^T\)
is the motion field (velocity vector) v, we can write the basic equation of optical flow, the Image Brightness Constancy Equation (IBCE)
\(v_x ∂E/∂x + v_y ∂E/∂y + ∂E/∂t = 0\)
where v_x = ∂x/∂t, and v_y = ∂y/∂t, the x and y components of the motion field, defined as the velocity with which fixed points in the scene move across the image plane. The motion field does not in general correspond to the true 3D motion of scene points. They correspond only in the case where an object point is moving only in the plane perpendicular to the optical axis (no depth movement or rotational movement out of that plane).
Motion field of rigid objects
Typically, the image brightness partials ∂E/∂x, ∂E/∂y and ∂E/∂t are estimated from the image sequence and plugged into this equation to get the motion field.
- Eg: Brightness values in the same image region in two successive frames IM(i,j,k), IM(i,j,k+1) are:
...10 16 12... ...10 15 12... ...12 14 11... ...13 15 14... ...15 14 10... ...17 14 12... IM(i,j,k) IM(i,j,k+1)
Using first forward difference approximation to estimate the partials, for the pixel at the center of this region at time k,
∂E/∂x ≅ IM(i,j+1,k) - IM(i,j,k) = 11-14 = -3
∂E/∂y ≅ IM(i-1,j,k) - IM(i,j,k) = 16-14 = +2
∂E/∂t ≅ IM(i,j,k) - IM(i,j,k+1) = 15-14 = +1
So
-3v_x + 2v_y + 1 = 0 by IBCE
But there is an obvious problem in using the IBCE to get v_x and v_y, the x and y components of the motion field: for a given point (x,y,t) in the sequence, this constitutes just one equation in two unknowns v_x and v_y.
Let \([v_x, v_y]^T\) be the actual motion field and \([v_x', v_y']^T\) be any vector orthogonal to the image brightness gradient
\([∂E/∂x, ∂E/∂y]^T\).
Then we can add any amount of the orthogonal vector to a solution of the image brightness constancy equation and still have a solution, since
\(([v_x, v_y] + a [v_x', v_y'])^T [∂E/∂x, ∂E/∂y] + ∂E/∂t = 0\)
Thus, from the IBCE we can only determine the component of the motion field in the direction of the spatial image gradient. The component of the motion field in the direction orthogonal to the image gradient direction is not revealed by solving the IBCE.

Barber pole illusion

Aperture problem

Solving the image brightness equation
Our plan is to gather an image database E(x,y,t), compute the partials of brightness E, and use the IBCE
\(v_x ∂E/∂x + v_y ∂E/∂y + ∂E/∂t = 0\)
to approximate the normal component of the motion field v(x,y) at each t. We will designate the normal component as the 2-D vector v'.
As noted earlier, the normal component of v is parallel to the image gradient
\(∇E = [∂E/∂x, ∂E/∂y]^T\).
So we can write v' as
\(v' = v_n (∇E)/||∇E||\)
where
||*|| denotes the Euclidean norm. Here \(v_n\) is a non-negative scalar that indicates the length of the normal component vector v', which points in the ∇E direction.
∇E/||∇E|| is the unit vector pointing in the direction of the image gradient ∇E.
Plugging v' into the IBCE,
\(v_n (∇E)^T(∇E)/||∇E|| + E_t = 0\)
or
\(v_n = - E_t/||∇E||\)
We can compute the normal component easily once we have the image spatial brightness gradient ∇ E, and the temporal brightness derivative \(E_t\). Substituting \(v_n\) back, the final expression for the normal component v' is
\(v'= v_n (∇E)/||∇E||= -E_t (∇E)/||∇E||^2\)
Eg: At a given (x,y,t) \(∇E= [2,-1]^T\) and \(E_t=3\).
Then \(v_n=-3/\sqrt{5}\) and \(v'=[-6/5,3/5]^T\). It is important to keep in mind that v' is only part of the desired motion field, the part normal to the image gradient ∇E at (x,y,t). There is in general a second component, which is perpendicular to the image gradient ∇E, which the IBCE cannot help to determine.
Sometimes the normal component is all you need. For instance, in the case of purely translational motion in the (x,y) plane, the motion field vectors of a rigid body are all equal, and this can be used to determine the motion field from its normal component.
- Eg: x-y plane translational motion of a rigid body:

Since the body is rigid and undergoing pure translational x-y motion, all motion field vectors must be identical. So the motion field at each point can be determined by combining the normal component there with the normal component determined elsewhere at any point where the image gradient is orthogonal to its value at the given point.
But in more general cases, we need to approximate the complete motion field, not just the normal component. We will refer to an approximation of the motion field based on image brightness partials as an optical flow field.
Before developing methods for computing optical flow, it should be noted that the true motion field v does not exactly satisfy the IBCE, even in the simplest case. It is shown in Trucco, for instance, that for Lambertian surfaces and a single point source of illumination infinitely far away,
\(v_x ∂E/∂x + v_y ∂E/∂y + E_t = ρ I^T(\omega \times n)\)
where \(\rho\) is the albedo, I the illumination vector, \(\omega\) (omega) is the angular velocity vector, n the surface normal, and x the vector product (8.21 p 194).
So even in this simplest of cases, only if the object motion is pure translational (\(\omega=0\)) will the IBCE be correct.
While only an approximation, the optical flow field that satisfies the IBCE often is, however, a useful approximation to the motion field. This is often true even in more complex cases such as multiple local illumination sources, projective projection geometry, non-rigid body motion and modest amounts of rotation. Much work has gone into the design of optical flow algorithms that use the information about the motion field it contains while minimizing the errors that come from the fact that optical flow is, at best, an approximation to the desired quantity, the motion field.
The constant flow algorithm
For rigid body motion, we may assume that over most small visible surface patches the motion field v is constant. This is exact if the rigid body is undergoing purely translational motion in the x-y plane, otherwise it's only true to a good approximation.
By writing the IBCE at each of nxn set of pixels in a small patch, we can change one equation in two unknowns to \(n^2\) equations in two unknowns and solve the now over-defined system by least squares. That is the core idea of the constant flow algorithm.
Writing the IBCE at pixels \(p_1, p_2 \ldots p_{n^2}\) on a small nxn patch, and assuming v is constant over the patch (this is called the constant flow assumption), let E(p) be the brightness at pixel location p and time t:
\(∇E(p_1)^T v + E_t(p_1) = 0\)
\(∇E(p_2)^T v + E_t(p_2) = 0\)
...
\(∇E(p_{n^2})^Tv + E_t(p_{n^2}) = 0\)
or Av-b=0 where A is \(n^2\)x2, b is \(n^2\)x1 and v is the common 2x1 unknown motion field for all pixels on this patch.
Then
\(A^TAv - A^Tb = 0\)
and we have an unique least squares solution
\(v'(p) = (A^TA)^{-1}A^T b\)
Note that v is the true unknown motion field and v' the optical flow field. They will be exactly equal only in the case where the image partials are known exactly without error or noise.
- Eg: From Barron, J.L. et. al., Performance of Optical Flow Techniques, IJCV, 12:1, 43-77, 1994.
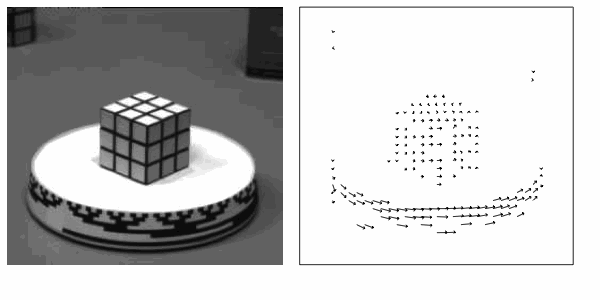
Notice that the motion vector estimates in regions of high local contrast such as the rim of the round table on which the Rubik's Cube sits are quite accurate while other regions, like the top of that table, are very poorly estimated.
The most common version of the constant flow algorithm uses a square mask centered about the point p. One project idea might be to used censored averaging of some kind to avoid using points on both sides of a rigid body bounding edge.
- Eg: Object undergoing (x,y,z) translation against a moving background. Averaging in the indicated circle would yield bad estimates.

Note that since calculations are done patch by patch independently,the constant flow algorithm does not actually require the entire object to be a rigid body undergoing pure translational motion, just that each patch be. Of course, if the object is not rigid undergoing pure translation, there will be formal contradictions between the treatment of overlapping patches. Thus we should say that constant flow is an approximation to the motion field based on the assumption of local rigid translation rather than global rigid translation.
The feature tracking method
The constant flow algorithm, a differential calculation, gives you a dense optical flow field output (one motion estimate per pixel) but is clearly going to be noisy, for two main reasons:
- The estimation of ∇E(p) and \(E_t(p)\) from E will be noisy;
- The IBCE is never exactly satisfied.
An alternative is the feature tracking class of algorithms, which have opposite characteristics: they output only a sparse optical flow, but (for well designed algorithms) the flow estimate is much less noisy. These algorithms rely on solving the correspondence problem (computing disparity) for prominent features. Disparity per unit time is a direct approximation to the desired motion field.

Structure from motion
Given a (sparse or dense) optical flow field, can we determine the structure of the rigid body being imaged? By structure we mean the 3-D coordinates of a set of surface pixels of the object.
1. From a sparse optical flow field:
Given a sparse optical flow field from a single object assumed to be moving as a rigid body and viewed in orthographic projection, we may use the following algorithm to compute both structure (the 3-D locations of each pixel in the sparse set), and the motion parameters of the object: its translation and rotation vectors. So this algorithm should really be called "motion and structure from sparse optical flow."
Let \(p_{ij}=[x_{ij},y_{ij}]^T\), i=1..N frames, j=1..n pixels be the set of pixels with known disparities. Begin by computing the centroid \(p_i\) for each frame by averaging the n pixels \(p_{ij}\).
The motion of a 3-D rigid body is governed by
\(v = -T - \omega \times p\)
where T is the translation and \(\omega\) the rotation vector, x is vector product, and v is the velocity vector at location p (v, T, w and p are all 3-D vectors). The vector product is computed by the "right-hand-rule" to be
\(\omega \times p = [ \omega_y p_z - \omega_z p_y, \omega_z p_x - \omega_x p_z, \omega_x p_y - \omega_y p_x]^T\)
First consider translation T. The x and y components are just the disparity rates
\([T_{xi},T_{yi}]^T = T_i = (p_{i+1}-p_i)/(t_{i+1}-t_{i})\)
The z component of T cannot be computed, as we are assuming orthographic projection.
- Eg: A point undergoing only z-translation will not move in orthographic projection. Two points with identical T and \(\omega\) vectors except for T_z will, by superposition, move identically.
Now to get the rotation and shape parameters, define the central or registered coordinates \(\tilde{x}_{ij}\), \(\tilde{y}_{ij}\)
\([\tilde{x}_{ij},\tilde{y}_{ij}]^T = [x_{ij},y_{ij}]^T - p_i\) for i=1..N, j=1..n
Then with \(\tilde{X}\) and \(\tilde{Y}\) the \(\tilde{x}_{ij}\) and \(\tilde{y}_{ij}\) matrices, define the registered measurement matrix \(\tilde{W}\)
\(\tilde{W} = [X^{~T},Y^{~T}]^T\)
It turns out (see Trucco 203-208) that \(\tilde{W}\) can be factorized as a product of just what we want: a rotation matrix R and a structure matrix S
\(\tilde{W} = RS\)
where
\(R = [i_1 \ldots i_N, j_1 \ldots j_N]^T\)
and the rotation of frame k is specified by the orthogonal axes \((i_k, j_k, i_k \times j_k)\)
and
\(S = [P_1 \ldots P_n]\)
where \(P_1\) is a vector in \(R^3\) corresponding to the initial position at \(t=t_1\) of the point \(p_{1j}, j=1 \ldots N\), etc.
2. From a dense optical flow field: select a set of n points, correspond them over the N frames, and proceed as above.