Academic papers, slides of some talks, ongoing FAQ.
New Study of Freestyle Chess, as referenced in the book Average is Over by Tyler Cowen, and more evidence against rating inflation.
Keys to understanding the issues:
the principle below and the Parable of the Golfers.
How closely do a person's actions agree with recommendations made by one or more advisors? Which advisor(s) are preferred, or is the person marching to his/her own drummer? Which agreements with particular recommendations are the most significant?
In chess, the advisor is a computer chess program, and not marching to one's own drummer in a competitive game is cheating. This has regrettably become a real problem even at the highest levels of our beautiful game. The recommendations are evaluations of possible moves given by the program, saying which side would be how-many hundredths of a Pawn ahead.
The main statistical principle which these pages show has been misunderstood by the chess world is that a move that is given a clear standout evaluation by a program is much more likely to be found by a strong human player. And a match to any engine on such a move is much less statistically significant than one on a move given slight but sure preference over many close alternatives. Case in point, 2/23/09: The mention of Rybka in GM Mamedyarov's protest letter at the 2009 Aeroflot Open was evidently this kind of misunderstanding, as demonstrated here (data viewable here).
The main scientific challenge is how to translate from evaluations into prior probabilities that recommendations would be followed by (non-colluding!) players---or whether this issue can be skirted and how. Estimating "priors" is a fundamental problem in Bayesian statistics and scientific inference, but the chess case lacks "repeatability" of experiment and some numerical properties that promote easier success in other applications. Even simpler problems such as the best choice of a distributional distance measure of (dis)agreement, of which (classical) fidelity is just one, are subjects of current debate in professional literature.
This work also has a positive component, for studying human decision-making and assessing skill. Largely because the model is "chess-neutral", using only the analysis evaluations as inputs, it can apply to many areas, including multiple-choice tests and trading analysis. See the research description, longer overview, papers, and talks. Within chess it can be used for player training and (self-)analysis, as well as historical rating comparison. For one example, see this plaintext IPR Chart of 23 top players in the baker's-dozen of super-tournaments we have enjoyed since the first FIDE Grand Prix event in London last autumn. It certainly shows that Magnus Carlsen has been playing up to his unprecedentedly high rating(!), and shows the overall reasonableness of the model.
(1/13/13) Letter and Report to the Association of Chess Professionals in the wake of allegations against Mr. Borislav Ivanov from the Dec. 2012 Zadar Open. Comparison with Houdini 3 Single-PV test results on some other "mercurial" performances.
(1/23/12) I have been involved privately with the Feller-Hauchard-Marzolo case since the news became public a year ago here (see also news-aggregation here). There is no real news I know beyond what appeared on Christophe Bouton's blog on 30 November (Google translate into English), where I am also referenced for work forwarded to the FIDE Ethics Committee. To re-cap what my cover statement here has said since 1/23/11: Bear in mind the policy stated elsewhere on this site that statistical evidence should be secondary to physical or observational evidence of possible wrongdoing. The FFE and the principals involved are entitled to the privacy of a formal investigation without unwarranted speculation. Science in the public interest will respect these boundaries.
(3/20/12) New York Times article; technical FAQ with
supplementary information.
These pages provide what still (4/16/07---present) seems to be the only public and scientifically presented quantitative testing of cheating allegations that have rocked the chess world since summer 2006. Primary source links are given for allegations and their coverage, in these major cases tested so far:
This site is doing both theory and experiment---and currently the experimental methodology must be both painstaking and flexible in order to be realistic for the alleged activities being modeled. Early status (4/16/07) had the theory in its early stages, but with data on this site that already seems to speak for itself, when gathered carefully and exhibited fully. Current status (1/23/11) is that a model able to give robust confidence intervals is within reach.
Kenneth W. Regan is an Associate Professor with tenure in the Department of Computer Science and Engineering, University at Buffalo (SUNY). He works in Computational Complexity Theory and other fields of Information Theory and (Pure) Mathematics that are relevant to this work. He also holds the title of International Master from the World Chess Federation (FIDE), and according to this list can claim to be the highest chess-rated active professional in these fields.
GM Jonathan Mestel is in Applied Math :-). Regan's non-confidential assistants are named on relevant pages.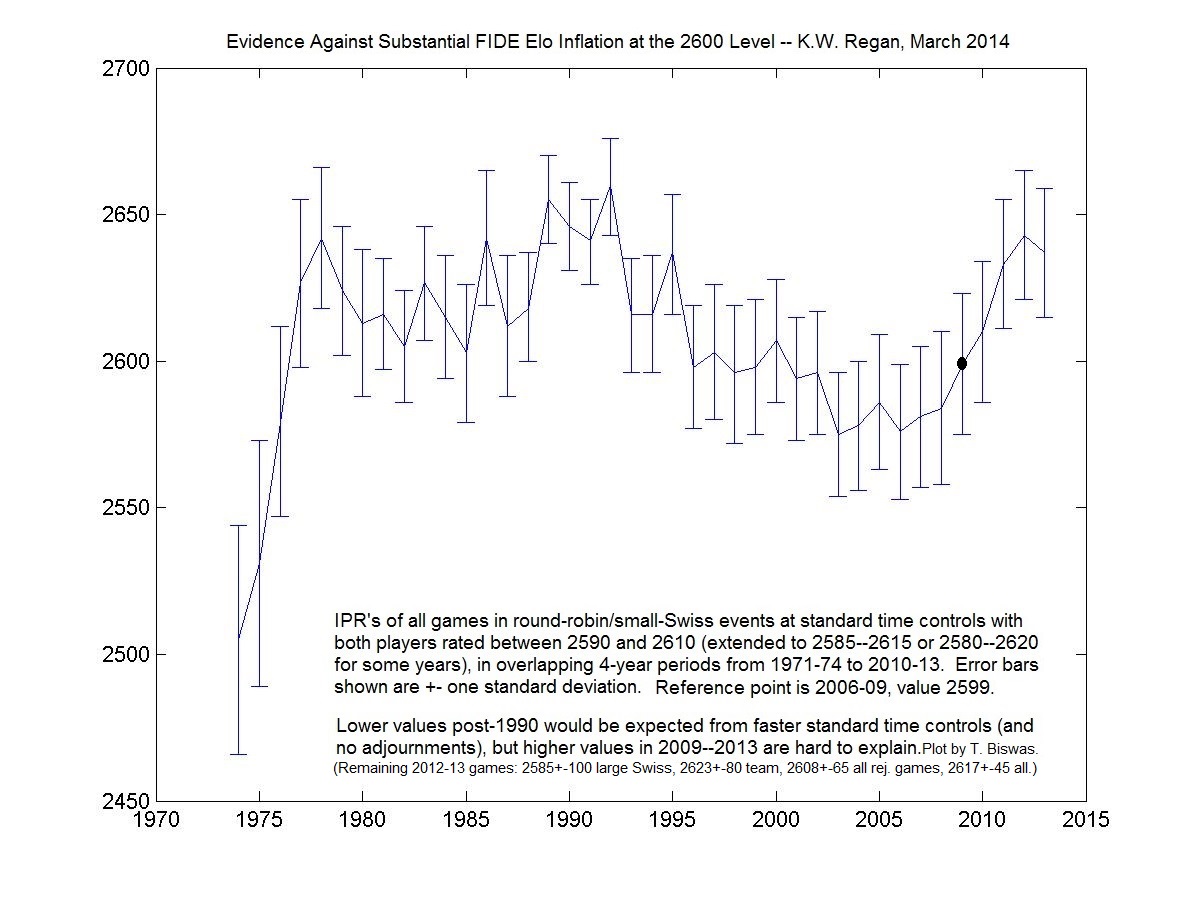{kind=link}