CSE4/587 Spring 2017
1. "Hmm..What is Data-intensive Computing?"
The phrase was initially coined by National Science Foundation (NSF).
This particular definition sets a very nice context for our course.
Before we go further let's set the context. We are living in a golden era in computing.
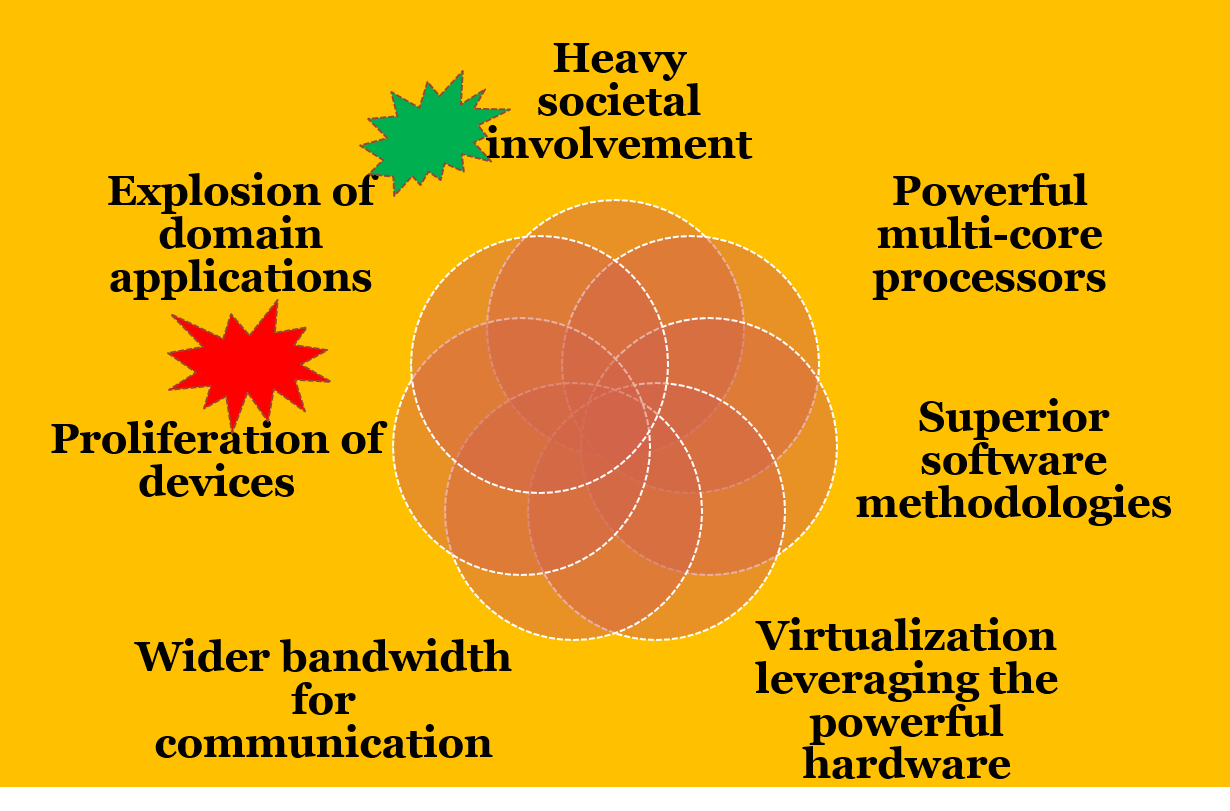
2. Given this context, how can you characterize data..big data?
Volume, velocity, variety, veracity (uncertainty) (Gartner, IBM) as illustarted here
3. How are we addressing the increased complexity in data?
Tremendous advances have taken place in statistical methods and tools, machine learning and data mining approaches, and internet based dissemination tools for analysis and visualization. Many tools are open source and freely available for anybody to use.More importantly, newer storage models, processing models, big data analytics and cloud infrastructures have emerged.
4. Okay. Can you give us some examples of data-intensive applications?
- Search engines
- Recommendation systems:
CineMatch of Netflix Inc. movie recommendations
Amazon.com: book/product recommendations - Biological systems: high throughput sequences (HTS)
Analysis: disease-gene match
Query/search for gene sequences - Space exploration
- Financial analysis
5. What about the scale of data?
Intelligence is a set of discoveries made by federating/processing information collected from diverse sources. Information is a cleansed form of raw data.
For statistically significant information we need reasonable amount of data.
For gathering good intelligence we need large amount of information.
As pointed out by Jim Grey in the Fourth Paradigm book enormous amount of data is generated by the millions of experiments and applications. Thus intelligence applications are invariably data-heavy, data-driven and data-intensive.
Lets discuss algorithm vs data. "More data beats better algorithms".
6. How about data applications? Characteristics of intelligent applications
Google search: How is different from regular search in existence before it? It took advantage of the fact the hyperlinks within web pages form an underlying structure that can be mined to determine the importance of various pages.
Restaurant and Menu suggestions: instead of “Where would you like to go?” “Would you like to go to CityGrille”? Learning capacity from previous data of habits, profiles, and other information gathered over time.
Collaborative and interconnected world inference capable: facebook friend suggestion Large scale data requiring indexing
…Do you know amazon is going to ship things before you order?
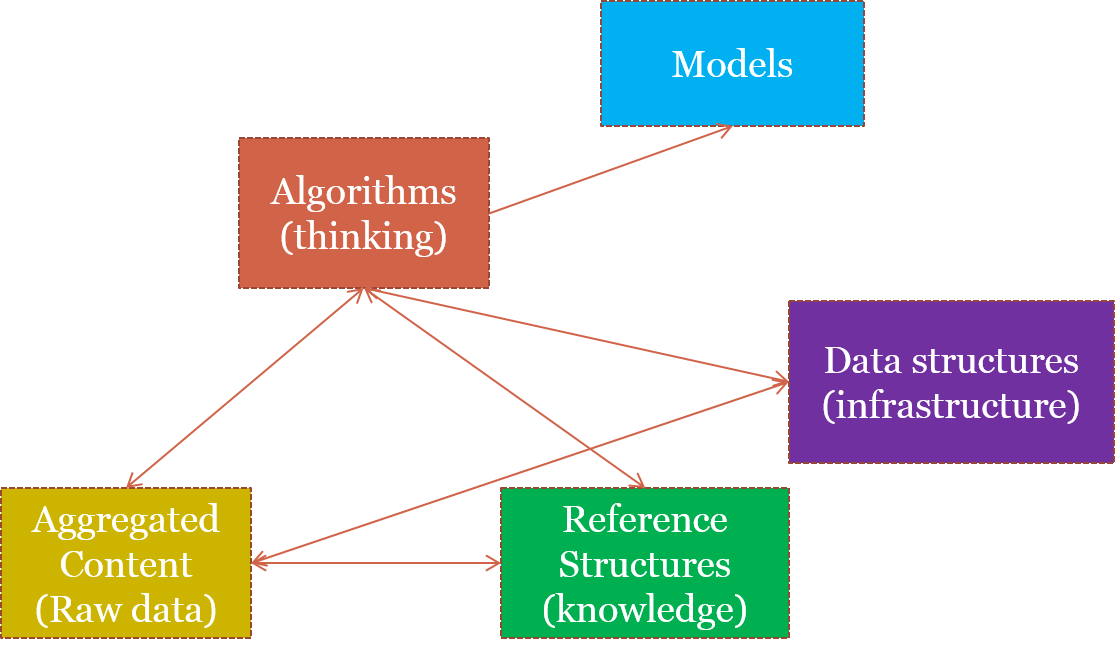
7. Data-intensive Computing Model (From Lin & Dyer)
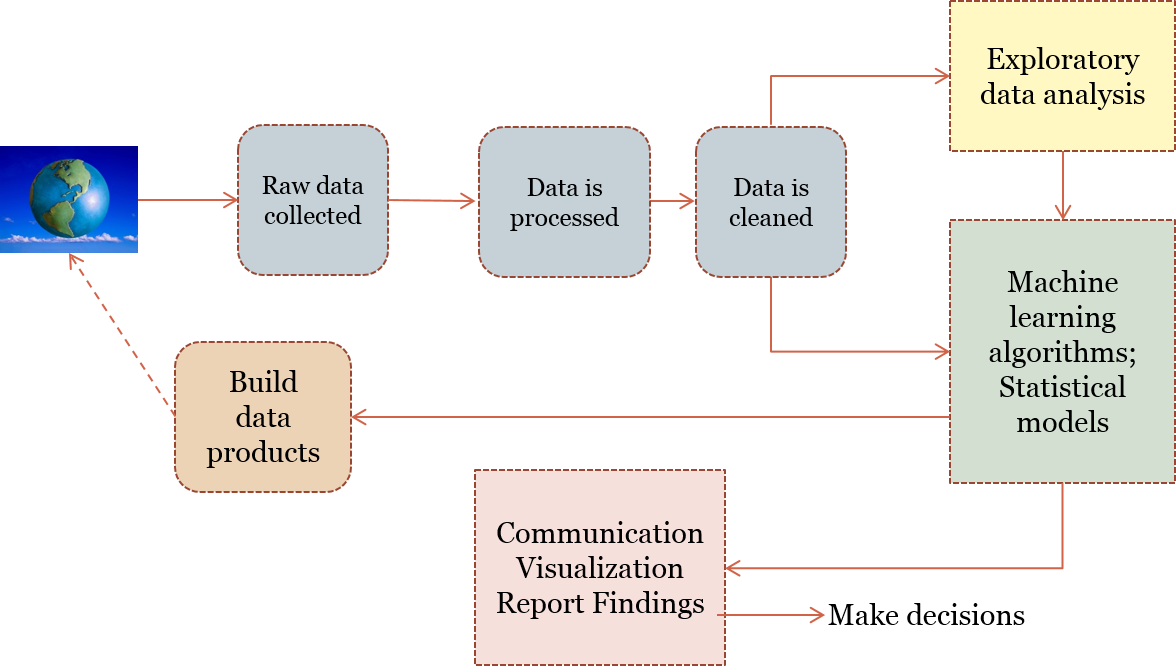
8. Data Science Process I(Adapted from Doing Data Science)
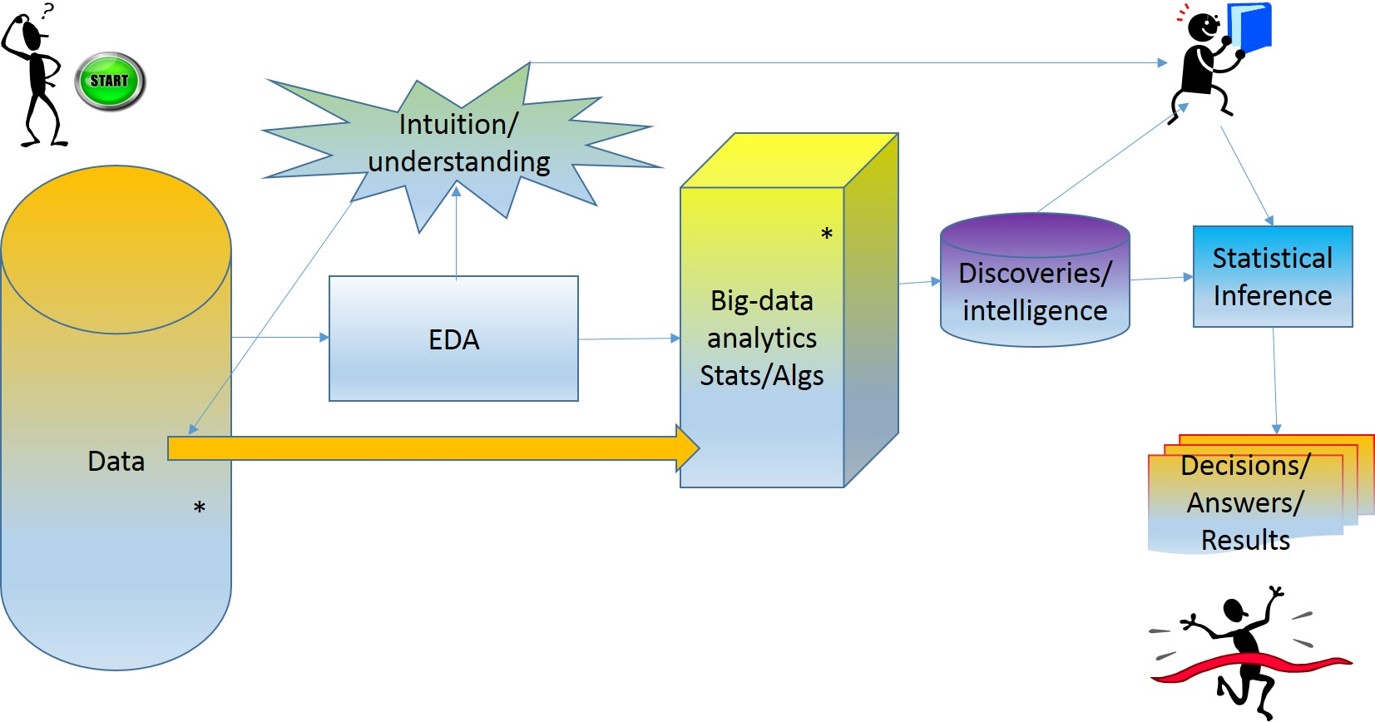
9. Data Science Process II
10. How do we plan to do it?
Small units of (concepts)learning, reinforced in the labs, and one term project as a capstone.