LIBSVX
Supervoxel Library
Current Version: 3.0:12/2013

Jason J. Corso
| News/Updates | |
| Overview | |
| Library Methods | |
| Streaming Methods | |
| Offline Methods | |
| Flattening Methods | |
| Benchmark | |
| Code / Download | |
| Publications | |
| Tutorial |
LIBSVX: A Supervoxel Library and Benchmark for
Early Video Processing
Primary Contributors: Chenliang
Xu and Jason Corso
(Email
Contact)
 Overview:
Images have many pixels; videos have more. Despite the strong
potential of supervoxels to enhance video analysis and the successful
usage of superpixel in many aspects of image understanding,
supervoxels have yet to become mainstream in video understanding
research. Two likely causes for this are (1) the lack of an available
implementation for many supervoxels methods and (2) the lack of solid
evaluation results or a benchmark on which to base the choice of one
supervoxel method over another. In this project, we overcome both of
these limitations: LIBSVX is a library of supervoxel and video
segmentation methods coupled
with a principled evaluation benchmark based on quantitative 3D
criteria for good supervoxels. This is the code we used in
support of our CVPR 2012, ECCV 2012 and ICCV 2013 papers. See the
papers for a full description of the methods and the metrics; this
page is intended to give an overview and provide the code with usage
and output examples.
Overview:
Images have many pixels; videos have more. Despite the strong
potential of supervoxels to enhance video analysis and the successful
usage of superpixel in many aspects of image understanding,
supervoxels have yet to become mainstream in video understanding
research. Two likely causes for this are (1) the lack of an available
implementation for many supervoxels methods and (2) the lack of solid
evaluation results or a benchmark on which to base the choice of one
supervoxel method over another. In this project, we overcome both of
these limitations: LIBSVX is a library of supervoxel and video
segmentation methods coupled
with a principled evaluation benchmark based on quantitative 3D
criteria for good supervoxels. This is the code we used in
support of our CVPR 2012, ECCV 2012 and ICCV 2013 papers. See the
papers for a full description of the methods and the metrics; this
page is intended to give an overview and provide the code with usage
and output examples.
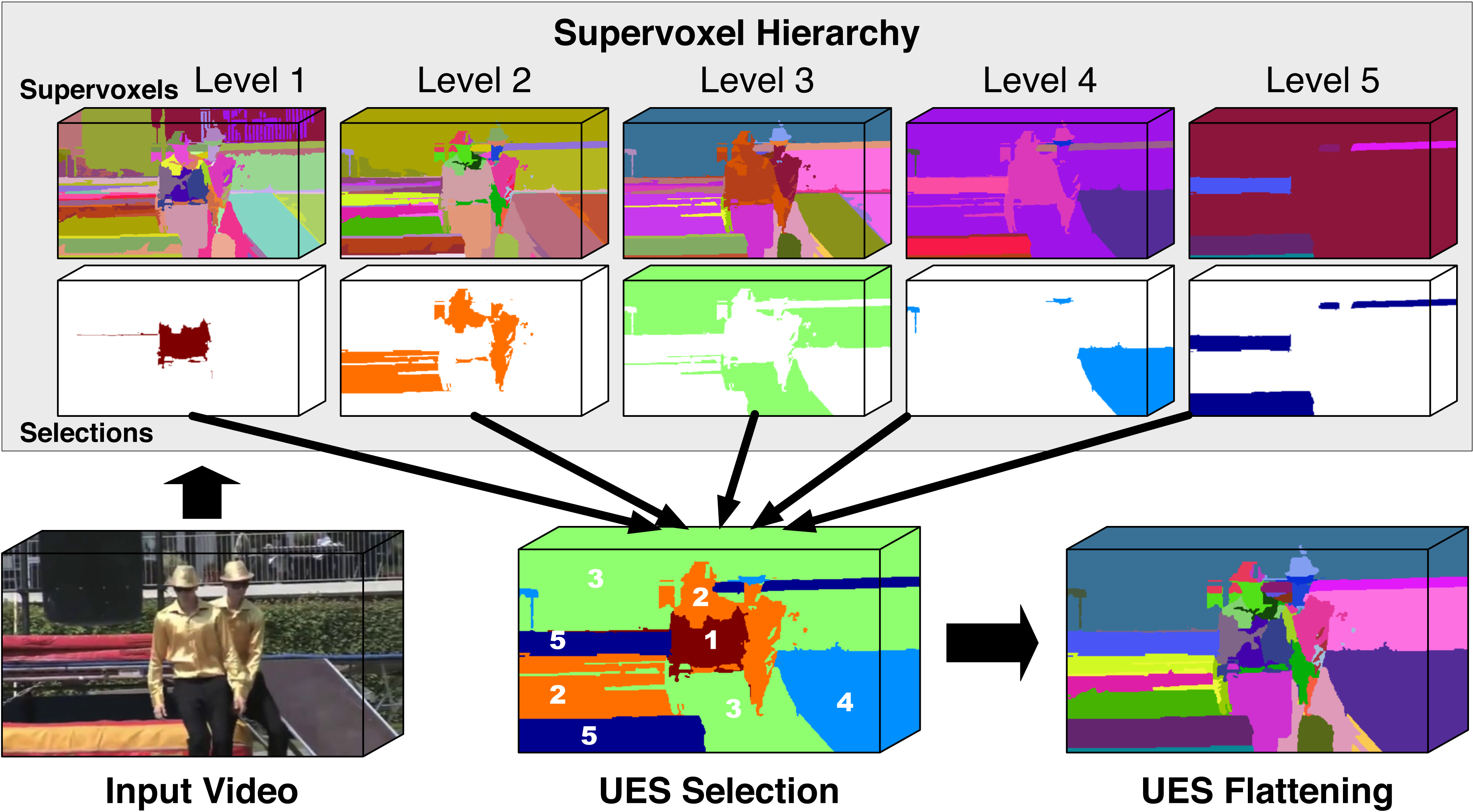
What's new in LIBSVX 3.0? We include the method in our ICCV 2013 paper for flattening supervoxel hierarchies by the uniform entropy slice (UES). UES flattens a supervoxel hierarchy into a single segmentation such that it overcomes the limitations of trivially selecting an arbitrary level. It selects supervoxels in the hierarchy that balances the relative level of information in the final segmentation based on various post hoc feature criteria, such as motion, object-ness or human-ness. Three challenging video examples (with two actors in each) used in our ICCV 2013 paper are also included in this release. We also include bug-fixes in gbh, gbh_stream and swa.
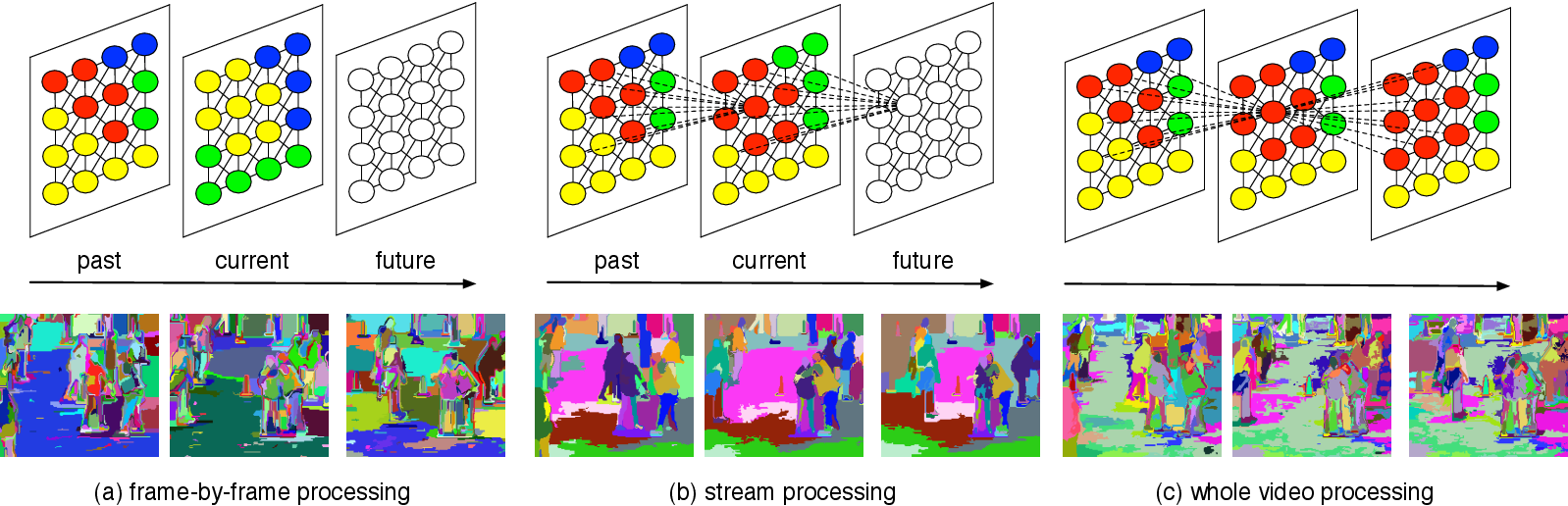
 What's new in LIBSVX 2.0?
The use of video segmentation as an early processing step in video analysis lags
behind the use of image segmentation for image analysis, despite many available
video segmentation methods. A major reason for this lag
is simply that videos are an order of magnitude bigger than images; yet most
methods require all voxels in the video to be loaded into memory, which is
clearly prohibitive for even medium length videos. We address this limitation
by proposing an approximation framework for streaming hierarchical video
segmentation motivated by data stream algorithms: each video frame is
processed only once and does not change the segmentation of previous frames.
We implement the graph-based hierarchical segmentation method within our
streaming framework; our method is the first streaming hierarchical video
segmentation method proposed. This is the code we used in support of
our ECCV 2012 paper.
What's new in LIBSVX 2.0?
The use of video segmentation as an early processing step in video analysis lags
behind the use of image segmentation for image analysis, despite many available
video segmentation methods. A major reason for this lag
is simply that videos are an order of magnitude bigger than images; yet most
methods require all voxels in the video to be loaded into memory, which is
clearly prohibitive for even medium length videos. We address this limitation
by proposing an approximation framework for streaming hierarchical video
segmentation motivated by data stream algorithms: each video frame is
processed only once and does not change the segmentation of previous frames.
We implement the graph-based hierarchical segmentation method within our
streaming framework; our method is the first streaming hierarchical video
segmentation method proposed. This is the code we used in support of
our ECCV 2012 paper.
The paper also included results from the mean shift method from Paris et al. (CVPR 2007), which is available directly from http://people.csail.mit.edu/sparis/#code.
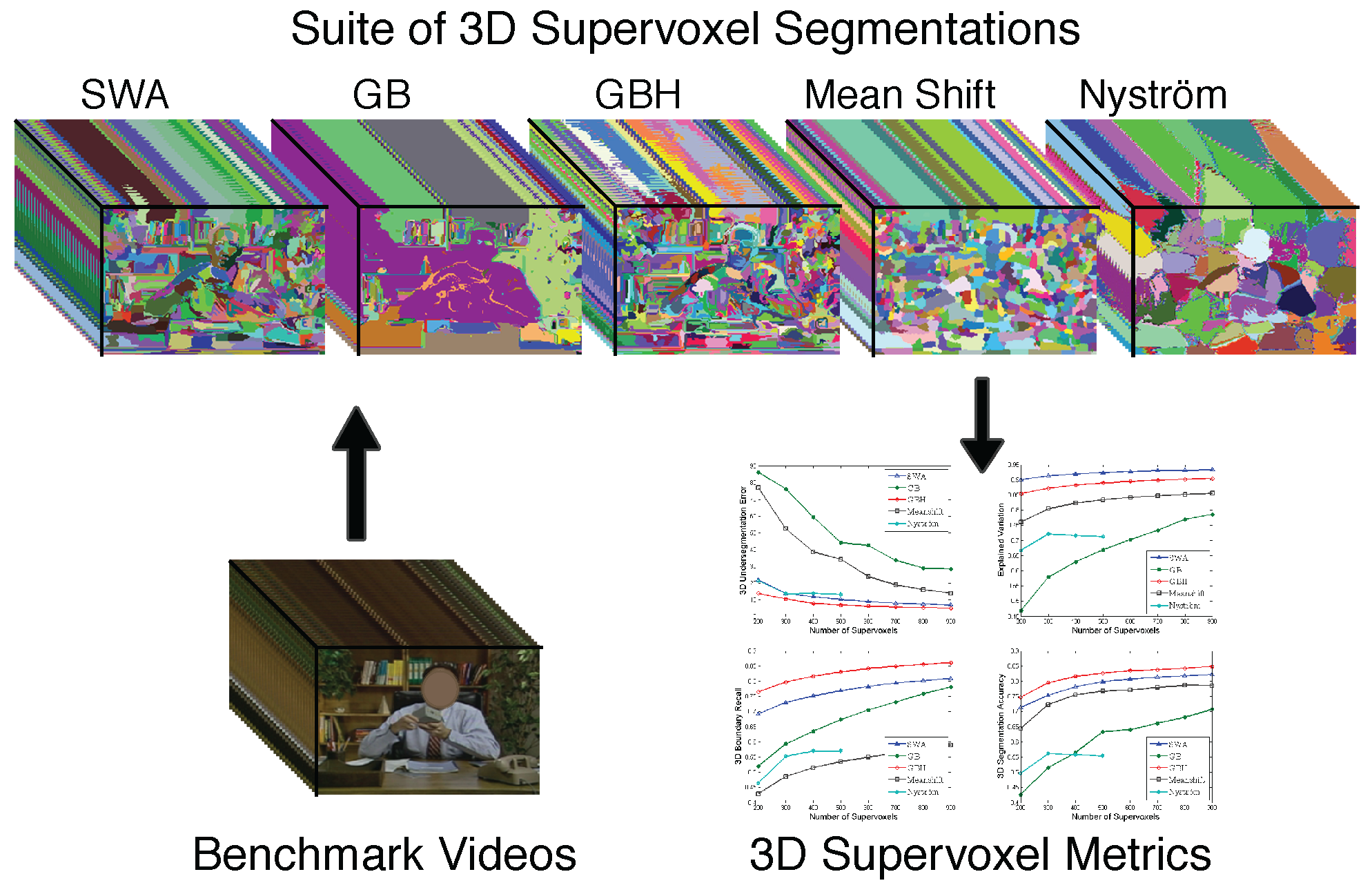
Some example output comparative montages of all the methods are below (click each for a high-res version).
Overview:
Images have many pixels; videos have more. Despite the strong
potential of supervoxels to enhance video analysis and the successful
usage of superpixel in many aspects of image understanding,
supervoxels have yet to become mainstream in video understanding
research. Two likely causes for this are (1) the lack of an available
implementation for many supervoxels methods and (2) the lack of solid
evaluation results or a benchmark on which to base the choice of one
supervoxel method over another. In this project, we overcome both of
these limitations: LIBSVX is a library of supervoxel and video
segmentation methods coupled
with a principled evaluation benchmark based on quantitative 3D
criteria for good supervoxels. This is the code we used in
support of our CVPR 2012, ECCV 2012 and ICCV 2013 papers. See the
papers for a full description of the methods and the metrics; this
page is intended to give an overview and provide the code with usage
and output examples.
What's new in LIBSVX 3.0? We include the method in our ICCV 2013 paper for flattening supervoxel hierarchies by the uniform entropy slice (UES). UES flattens a supervoxel hierarchy into a single segmentation such that it overcomes the limitations of trivially selecting an arbitrary level. It selects supervoxels in the hierarchy that balances the relative level of information in the final segmentation based on various post hoc feature criteria, such as motion, object-ness or human-ness. Three challenging video examples (with two actors in each) used in our ICCV 2013 paper are also included in this release. We also include bug-fixes in gbh, gbh_stream and swa.
News / Updates
- 17 Dec. 2013 -- LIBSVX 3.0 Release, includes the uniform entropy slice method for flattening segmentation hierarchies (GBH and SWA) and bug-fixes for gbh, gbh_stream, and swa modules.
- 30 July 2012 -- LIBSVX 2.0 Release, includes graph-based streaming hierarchical methods that can handle videos of arbitrary length.
- 25 June 2012 -- LIBSVX wins Best Open Source Code Award 3rd Prize at CVPR 2012.
- 15 June 2012 -- LIBSVX wins best demo at the 2nd Greater NY Multimedia and Vision Meeting.
Library Methods:
The library includes five methods (one streaming and four offline). Code (C++ unless otherwise noted) is provided for all of the methods in the download.Streaming Algorithm:
Streaming methods require only constant memory (depends on the streaming window range) to execute the algorithm which makes it feasible for surveillance or to run over a long video on a less powerful machine. The solution to a streaming method is an approximation the solution of an offline algorithm, which assume the entire video can be loaded into memory at once.- Graph-based Streaming Hiearchical Video Segmentation. Implements the graph-based hierarchical segmentation method (StreamGBH) within the streaming framework (our ECCV 2012 paper.).
 Example of long-term coherency of StreamGBH; (a) is the original
video, (b) layer 5, (c) layer 10, (d) layer 15. Click for higher-res.
Example of long-term coherency of StreamGBH; (a) is the original
video, (b) layer 5, (c) layer 10, (d) layer 15. Click for higher-res.

Example of StreamGBH for shot-detection. (a) is the original video, (b) layer 5, (c) layer 10, (d) layer 15. Click for higher-res. |
Offline Algorithm:
Offline algorithms require the video to be available in advance and short enough to fit in memory. It loads the whole video at once and processes afterwards. Under most circumstances, it gives better segmentation results than the corresponding streaming algorithm since it is aware of the whole video. The library includes original implementations of the following four methods.- Graph-Based. Implements the Felzenszwalb and Huttenlocher (IJCV 2004) directly on the 3D video voxel graph.
- Graph-Based Hierarchical. Implements the Grundman et al. (CVPR 2010) paper that performs the graph-based method iteratively in a hierarchy. At each level t in the hierarchy, (1) histogram features are used (rather than raw pixel features) and (2) the graph is built with the elements from level t-1 as input graph nodes.
- Nyström Normalized Cuts. Implements the Fowlkes et al. (TPAMI 2004)) approach of using the Nyström approximation to solve the normalized cuts (Shi et al. TPAMI 2000) grouping criterion. Our implementation is in Matlab.
- Segmentation by Weighted Aggregation. Implements the Sharon et al. (CVPR 2001, NATURE 2006) hierarchical algebraic multigrid solution to the normalized cut criterion in a 3D manner as was done in Corso et al. (TMI 2008). Multiscale features are also used as the hierarchical computation proceeds. We are grateful to Albert Chen and Ifeoma Nwogu for their contributions to this part of the code.
The paper also included results from the mean shift method from Paris et al. (CVPR 2007), which is available directly from http://people.csail.mit.edu/sparis/#code.
Some example output comparative montages of all the methods are below (click each for a high-res version).

|

|

|

|
Flattening Algorithm:
- Uniform Entropy Slice. This method seeks a selection of supervoxels that balances the relative level of information in the selected supervoxels based on some post hoc feature criterion such as object-ness. For example, with this criterion, in regions nearby objects, the method prefers finer supervoxels to capture the local details, but in regions away from any objects we prefer coarser supervoxels. The slice is formulated as a binary quadratic program. Code is included for four different feature criteria, both unsupervised and supervised, to drive the flattening.
Benchmark:
We also provide a suite of metrics to implement 3D quantitative criteria for good supervoxels. The metrics are implemented to be application independent and include 3D undersegmentation error, 3D boundary recall, 3D segmentation accuracy, mean supervoxel duration and explained variation. Along with the metrics, we incorporate scripts and routines to process through the videos in the following three data sets.- SegTrack From Tsai et al. (BMVC 2010), this data set provides a set of human-labeled single-foreground objects with the videos stratified according to difficulty on color, motion and shape. SegTrack has six videos, an average of 41 frames-per-video (fpv), a minimum of 21 fpv and a maximum of 71 fpv. It is available at http://cpl.cc.gatech.edu/projects/SegTrack/
- Chen Xiph.org This data set is a subset of the well-known xiph.org videos that have been supplemented with a 24-class semantic pixel labeling set (the same classes from the MSRC object-segmentation data set [36]). The eight videos in this set are densely labeled with semantic pixels and have an average 85 fpv, minimum 69 fpv and maximum 86 fpv. This data set allows us to evaluate the supervoxel methods against human perception. This data set has been released from our group in 2009 and we hence include it with the download of this library. More information on it is available at http://www.cse.buffalo.edu/~jcorso/r/labelprop.html.
- GaTech This data set was released with the Grundman et al. CVPR 2010 paper. It comprises 15 videos of varying characteristics, but predominantly with a small number of actors in the shot. In order to run all the supervoxel methods in the library on the benchmark, we restrict the videos to a maximum of 100 frames (they have an average of 86 fpv and a minimum of 31 fpv). Unlike the other two data sets, this data set does not have a groundtruth segmentation, which has inspired us to further explore the human independent metrics. It is available at http://www.cc.gatech.edu/cpl/projects/videosegmentation/.
Code / Download:
- The current version of the library is downloadable here. This download includes all segmentation methods, the benchmark code, documentation, and the Chen xiph.org data set.
- A full set of example outputs are available here (from the tutorial).
- Archival:
Publications:
| [1] | C. Xu, S. Whitt, and J. J. Corso. Flattening supervoxel hierarchies by the uniform entropy slice. In Proceedings of the IEEE International Conference on Computer Vision, 2013. [ bib | poster | project | video | .pdf ] |
| [2] | C. Xu, C. Xiong, and J. J. Corso. Streaming hierarchical video segmentation. In Proceedings of European Conference on Computer Vision, 2012. [ bib | code | project | .pdf ] |
| [3] | C. Xu and J. J. Corso. Evaluation of super-voxel methods for early video processing. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2012. [ bib | code | project | .pdf ] |
| [4] | J. J. Corso, E. Sharon, S. Dube, S. El-Saden, U. Sinha, and A. Yuille. Efficient Multilevel Brain Tumor Segmentation with Integrated Bayesian Model Classification. IEEE Transactions on Medical Imaging, 27(5):629-640, 2008. [ bib | .pdf ] |