CSE 462/562: Database Systems (Spring 2022)
Project 4: Basic Query Processing
Assigned: Tuesday, 4/12/2022
Project due: Thursday, 5/5/2022, 11:59 pm EST
Write-up due:Saturday, 5/7/2022, 11:59 pm EST
Last updated: 5/5/2022
Updates (5/5/22) we will run the offline tests at 1 pm, and every 2 hours thereafter for today, until the project deadline.
Updates (5/1/22): we will increase the test frequency from 1x per day to 2x per day, at 1:00 am and 1:00 pm.
Updates: the score board for the tests that are unavailable on Autograder is now online (use the link above). Please review the new testing and grading section for details.
Also note: please import the new test files in
lab4_extsort_test_update.tar.xz (available now on Autolab),
and read the new testing and grading section for usage and instructions.
Another hint: use absl::GetFlag(FLAGS_sort_nways)
to get the number of ways for the invocation of external sorting
in the SortState implementation.
0. Getting Started
This project will be built upon your code for project 3. We provide a tarball with some new starter code which you need to merge with your project 3.
- Make sure you commit every change to Git and
git statusis clean - Download
lab4.tar.xzand extract it inside your repo. You should now have a directory calledlab4inside your repo ./lab4/import_supplemental_files.sh- commit the updates and make a tag/branch
The code should build without compilation errors once the
supplemental files are imported, but most of the additional tests are
likely to fail. You may list all the tests in your build directory using
the ctest -N command.
A few useful hints:
- Some parts of this project will heavily rely on your variable-length data page implementation from the previous projects. Note that this project also requires you to read and write a fair amount of code, so START EARLY.
- Code you have to write in this project will be scattered across a lot of files (much more than project 1 and project 2), while the absolute amount of code you will add is smaller. That said, you'll need to read a fair amount of code and look up the definitions and declarations in many different header files to come up with a solution. The Code Docs in the drop-down menu on the top will be a very useful resource.
- The description below is meant to be a brief overview of the tasks. Always refer to the special document blocks in the header and source files for a more detailed specification of how the functions should behave.
- You may add any definition/declaration to the classes or functions you are implementing, but do not change the signature of any public functions. Also, DO NOT edit those source files not listed in source files to modify below, as they will be replaced during tests.
- You may ignore any function/class that’s related to multi-threading and concurrency control since we are building a single-threaded DBMS this semester. Thus, your implementation doesn’t have to be thread-safe.
- We provide a list of tasks throughout
this document, which is a suggestion of the order of
implementation such that your code may pass a few more tests
after you complete a task. It, however, is not the only
possible order, and you may find an alternative order that
makes more sense to you. It is also possible that your code
still could not pass certain tests, which is supposed to
because of some unexpected dependencies on later tasks, in which
case you might want to refer to the test code implementation in the
test/directory. - If you're working in a team of two, you might want to first go through the list of tasks, agree on a big picture of design, and divide the implementation tasks into indepedent pieces. One strategy is to implement tasks that may be tested independently. Alternatively, you could also design the algorithm and data structures together, and identify independent components to complete. You may also come up with better ways of collaboration that makes more sense to you. In any case, the grade for the code implementation will be based the test result of your group's final submission.
1. Project Overview
In this project, you will work on the basic operators for query processing in Taco-DB. The goal of this project is to implement the physical plans and execution states for the rest of basic operators for query processing. In addition to the query oprerators, there are also two additional operators for inserting and deleting records from the tables. Note that they must maintain all the indexes over the table if any record is inserted or deleted.
To reduce your workload, we provide the implementation of a few operators for your reference. You might find them useful to read them before starting on the tasks. The operators that you DO NOT need to implement are listed below:
- Table Scan
- Projection
- Limit
- Temporary Table
- Table Insert
- Table Delete
The following is a list of the query operators that you need to implement. As always, we will provide a list of tasks to complete to guide you through the implementation, but you do not have to follow the ordering because these operators can be implemented independently and their test cases may be independent of each other.
- Selection (easy)
- Cartesian Product (easy)
- Aggregation (easy)
- Index Scan (not too hard). Make sure your B-Tree implementation works and link for B-Tree solution will be posted on Piazza by 4/15.
- Sort (hardest, using the external merge-sort algorithm)
At the end of this project, you should be able to programmatically construct query plans and execute them. Technically, you will have an (almost) fully functioning single-threaded database (without a SQL parser and an optional query optimizer) after this project. The main theme of this project is going to be quite different from the previous projects. It will focus less on the implementation of algorithms and manipulation of bytes. Rather it will focus more on the common engineering patterns and the memory management. After finishing the first a few operators, you will find all the others follow the same design pattern with subtle differences. Thus, you will find the others much easier to implement once you read and understand the provided implementation, and finish the first a few operators.
There are basic test cases for each of these operators (including the ones you do not need to implement), which are not meant to be comprehensive coverage test of your implementation. There will be test cases with a few more complex query plans that contain these basic operators to further test the the correctness of the implementation. There will also be a few hidden system tests over the TPC-H benchmark data with several simplified queries, which will use the basic operators you implemented for the physical plans. In order to pass those tests, you will likely need to extensively test your code using your own test cases. To help you with that, we will release project 5 early, where we will distribute a small scale TPC-H benchmark dataset and a few samples of how to write query plans in the test cases. The Autograder will not be able to run the system tests within a reasonable time, so we will run nightly tests on your latest submission about two weeks from the date the project is released and publish the test results on an anonymous score board for each group every day. We will share more details on the score board for system tests later.
1.1 Trees and Expression Trees
Source files to read:
include/utils/tree/TreeNode.hinclude/expr/ExprNode.hinclude/expr/optypes.h- All expression nodes as needed in
include/expr/*.handsrc/expr/*.cpp
Source files to modify: none
One of the core structures we use in query processing is the
trees. Its basic interfaces and utilities are defined in
TreeNode class. All expressions, physical plans,
and execution states inherit from it. To give a full example of
how to utilize this infrastructure, we provide our
implementation of the expression trees for your reference. The
following description assumes that you understand the basic
concepts of expression trees from any compiler or programming
language course, although you do not
need to know all the details in the actual implementation to
proceed. If not, you can find it from online resources or a
compiler textbook. It might also be helpful to use a few
running examples when you go through the code and the following
description.
Expressions trees represent expressions in the SQL language
(such as boolean expressions student.sid =
enrollment.sid, aggregation expressions
AVG(student.adm_year - 1900), arithmetic expressions
DATE '1995-01-01' + interval '5' day, and etc.).
Each operator in the expression tree is represented as an
subclass that inherits ExprNode.
To ensure
memory safety (specifically, no memory leakage), we always wrap it
around as a unique pointer. We use an
interpretation-based strategy to evaluate the expressions trees.
We first call the ExprNode::Eval() function at
the expression tree root with a record from its
outer query plan (e.g., the outer plan of an expression in the
target list of a projection operator is the projection operator).
Then each non-leaf level, recursively call the
ExprNode::Eval() function on its child nodes (denoting
the subexpressions), and apply its operator over the subexpression
values to produce its evaluation result.
The leaf level of an expression tree is always either a
Literal (which evaluates to a constant) or a
Variable (which evaluates a field value in the
record from the outer plan). We provide two overloads of
the ExprNode::Eval function on
serialized records (const char*) or deserialized records
(std::vector<NullableDatumRef>). The function always
returns a Datum as return value with full ownership (i.e., the Datum
itself manage the memory for any pointers of its data). To ensure that,
you can see there are DeepCopy() calls in a few
Eval() implementations. This ensures we make a Datum with
full memory ownership and will always self-manage its own memory for
memory safety and avoid memory leakage.
We will discuss the memory management in Taco-DB in more details on 4/12 and you may find the lecture to be useful. You may also find the concepts of rvalue references, move semantics, and smart pointers of C++ very useful when reading the code and continuing on for the rest of the lab. You may find many useful C++ references from CppReference, and in particular, reference, std::move(), std::unique_ptr, std::shared_ptr.
1.2 Physical Plans & Execution States
Source files to read:
include/plan/PlanNode.hinclude/execution/PlanExecState.hinclude/plan/X.h,include/execution/XState.h,src/plan/X.cpp,src/execution/XState.cpp, whereXis one of the following:- TableScan
- Projection
- Limit
- TempTable
- TableInsert
- TableDelete
Source files to modify:
include/plan/X.h,include/execution/XState.h,src/plan/X.cpp,src/execution/XState.cpp, whereXis one of the following:- Selection
- CartesianProduct
- Aggregation
- IndexScan
- Sort
This part of the work contains all the basic query operators
and table update actions in Taco-DB. There are only a few
specialized join operators not covered here, which we will work
on in project 5.
For each
operator/action, there will be a physical plan and its
corresponding execution state. The physical plan of an
operator/action stores all the essential information during
query plan construction
(e.g., its child plan, selection predicate, etc.), while
the plan execution state stores run-time information for running
the physical plan over a particular database instance. A new execution
state is created for every execution of a physical plan.
As you can see in the
abstract interface defined in PlanNode and
PlanExecState, a physical plan encodes the
information about the query itself and always contains an output
schema, while an execution state is
essentially an iterator in the volcano model and stores
the internal state of the iterator.
The biggest challenge in implementing these plans and execution states is to ensure memory safety. In particular, you need to make sure: (1) if a piece of memory can still be accessed, it must be valid for access (i.e., not deallocated); (2) when you finish using a piece of memory, it should be freed by its owner; (3) the total memory usage of the system should be bounded (we will limit the memory you can use in the tests and exceeding memory usage may get the test process terminated).
When you are implementing these classes, there are majorly two types of memory you have to take special care on:
Deserialized Records: Deserialized records are represented by
std::vector<NullableDatumRef>. You have to make sure all the fields (all instances ofNullableDatumRef) are pointing to a validDatumkept alive by its owner (usually that means it is stored in a local Datum variable or Datum container that is still in scope or a member Datum variable or Datum conatiner of some execution state object). You can ensure this by caching the current record pointed by an execution state internally through astd::vector<Datum>when necessary. Note that in many cases, you don’t have to cache these fields if you know theNullableDatumRefrefers to some Datum that is owned by its child execution state and will be kept alive when the reference is used. For instance,get_current_record()of selection can always safely return the deserializedstd::vector<NullableDatumRef>from its child without caching.Derived Schema: You may need a new schema in some physical operators. In these cases, the plan node should create a new schema and own the object by store it as an
std::unique_ptr<Schema>. You should always callSchema::ComputeLayout()on a newly created schema, because it can only serialize and deserialize records after that call. Do not useSchema::CollectTypeInfo()because the current design of the physical plan and execution state interfaces require any output schema to be able to serialize and deserialize records. Similarly, you don’t always need to create a new schema for a plan if you can directly borrow it from its child. For example, the output schema ofSelectionis exactly the same as its child’s.
You are given full freedom on how to implement the internals of these
classes, including class member, debugging utilities, memory management
strategy, etc. You only need to honor the abstract class contract
PlanNode for physical plans and PlanExecState
for execution states.
Note: Please read the documentation before the definition of these classes VERY CAREFULLY for more implementation details.
Also note that: you don't have to implement
the save_position()function and the one-argument overload of
rewind(DatumRef) function (but you do need to implement
the no-argument overload of rewind()) in this project.
They will only be needed in project 5.
We recommend the following order of implementing these operators:
Task 1: Read TempTable and
TempTableState for in-memory temporary tables.
Task 2: Read TableScan and
TableScanState for heap file based table scan.
Task 3: Implement Selection
and SelectionState for selection.
Task 4: Read Projection,
ProjectionState for projection.
Task 5: Implement CartesianProduct and
CartesianProductState for Cartesian products.
Task 6: Implement Aggregation
and AggregationState for aggregation without
group-by (we will not implement the group-by aggregation in
this semester).
Task 7: Read Limit and
LimitState for limiting output to the first N
rows.
Task 8: Read TableInsert,
TableDelete, TableInsertState, and
TableDeleteState for table insert and delete actions.
Task 9: Implement IndexScan and
IndexScanState for index-based table scan.
Task 10: Before proceeding with the
implemention of Sort and SortState
for sorting, please read and complete the tasks 11 and 12 in
Section 1.3.
A side note for sort operator: please use the value of
absl::GetFlag(FLAGS_sort_nways) in
src/execution/SortState.cpp as the default
number of merge ways for external sorting.
After finishing each of the implementation tasks above, it is very likely that you will be able to pass the corresponding class of tests for that operator.
After you pass all the individual operator/action tests, a final group of tests will verify if they will work together seamlessly. This ensures that memory safety is satisfied across the plan/execution state tree. Specifically, they are:
BasicTestCompositePlan.TestAggregationQueryBasicTestCompositePlan.TestJoinQuery
Finally, there will be a few hidden system tests over the TPC-H dataset with a few simplified queries. They will not be tested on Autograder. Rather, we will run the tests on your latest submission every day and post the results on an anonymous score board. We will provide more details once the score board is online (in 1 or 2 weeks).
1.3 External Merge-Sort
Source file to READ:
include/extsort/ItemIterator.h
Source files to modify:
include/extsort/ExternalSort.hsrc/extsort/ExternalSort.cpp
External sorting in Taco-DB is implemented as a separate
component
since it can be used in various scenarios. Specifically,
it sorts all items (raw byte arrays) provided by an
ItemIterator and returns a unique pointer of
ItemIterator that will iterate through all the
items from input in a user-given order. There are two arguments
given to configure the behavior of external sorting.
comp provides the comparator between two general
items, while merge_ways provides the number of
merge ways (as well as its memory budget to be
(merge_ways + 1) * PAGE_SIZE).
Task 11: Implement the external merge-sort.
You should read the two file ExternalSort.h
and ExternalSort.cpp. To reduce your workload,
you only need to implement the following functions:
ExternalSort::Sort()ExternalSort::MergeInternalRuns()
There are two stages in external sorting: (1) packing initial
runs, sorting them, and writing them to a temporary file; (2) recursively
read sorted runs from the last pass, and use a multi-way
merge algorithm to generate a new pass. Specifically, you should
limit the total amount of memory you allocated for
input/output buffers to (N + 1) * PAGE_SIZE
(N input buffers and 1 output buffer for each merge).
You only need two temporary files in the whole procedure: one for
writing out the newly generated pass; one remembers the last pass as an
input. You also need to remember the boundaries of sorted runs in the
input pass so that you know where to start in merging. Every time when a
new pass is generated and the old pass from which it is generated is not
needed, you can simply continue the next round by flipping the input and
output file. (Hint: you can use
m_current_pass and 1 - m_current_pass to do
this).
In the implementation of external sorting, you should
completely bypass the buffer manager (rather you should
allocate your own n_merge_ways + 1 pages of buffer
internally), and manage all the read/write to temporary files directly
through the File interface. This is because the buffer
manager only manages data access to main files. Besides, you want to use
VarlenDataPage to help you layout records in sorted runs
(so you don’t have to reinvent a new page layout). During the merge, you
will need to use a priority queue. You can directly leverage the
implementation provided by the C++ Standard Template Library.
Its detailed documentation can be found here.
(Hint: STL priority queue by default put items with
higher priority in the front.)
Note: Not every sorted run is full and don’t forget the incomplete run at the end.
Task 12: Implement the output iterator for external sorting. Specifically, you need to implement the following functions:
ExternalSort::OutputIterator::OutputIterator()ExternalSort::OutputIterator::~OutputIterator()ExternalSort::OutputIterator::Next()ExternalSort::OutputIterator::GetCurrentItem()ExternalSort::OutputIterator::SavePosition()ExternalSort::OutputIterator::Rewind()ExternalSort::OutputIterator::EndScan()
This iterator implementation will be very similar to
TableIterator and IndexIterator you have
already implemented. The only extra thing you want to pay attention to
is that this iterator should support rewinding to any position saved
before, which will be useful for implementing `Sort::rewind(DatumRef saved_position)`
in the next project. Note that the position information should be encoded in an
uint64_t, and these integers do not have to be continuous
even when two rewind locations are right next to each other.
(Question: Think about how to do this efficiently.)
After finishing Task 11 and Task 12, you should be able to pass the following tests and continue with task 10:
BasicTestExternalSort.TestSortUniformInt64AscBasicTestExternalSort.TestSortUniformInt64DescBasicTestExternalSort.TestSortUniformStringAscBasicTestExternalSort.TestSortUniformStringDesc
2. Write-up requirement
Each individual student needs to submit an independent write-up to UBLearns for the project design, division of implementation responsibility (no more than 1 page in letter size for design and coding responsibility). Please find the due date of the write-up at the beginning of this web page and submit a PDF document to UBLearns by the deadline. Please find a more detailed description of the requirements and a sample for the write-up on UBLearns.
Special requirements for this project: since there are many operators to implement in this project, please only describe the design of two of the operators that you find most challenging. The teammates on the same team do not need to write about the same operators. You should still describe the division of implementation responsibility for all tasks.
3. Testing and Grading (New)
In this project, we will use Autograder only for the basic tests that may finish in a short amount of time on Autograder, for which you may submit your code and get grading result at any time as before.
For the long-running tests unavailable on Autograder, including the external sorting basic tests and the TPC-H query system tests, we will run them at 1:00 am daily on the commit in your latest submission to Autograder. The test results are posted on the scoreboard once all the tests are finished, usually within a few hours after 1:00 am.
(Important!) to ensure the nightly tests pull the commit that you want to test, make sure the last submission to Autograder prior to 1:00 am every day is accepted with the correct commit ID. In particular, look for the following three lines in your test log on Autograder (two at the beginning and one at the bottom) and make sure the commit ID is the correct one:


The following figures show the screenshots of a sample scoreboard and provide an explanation of how to interpret the results. Note that group 1 is the reference implementation (solution). The timeout of a test case is usually set to be 2-3x of the running time of the reference implementation and the memory limit is set to a few thousand KB more than what it needs.
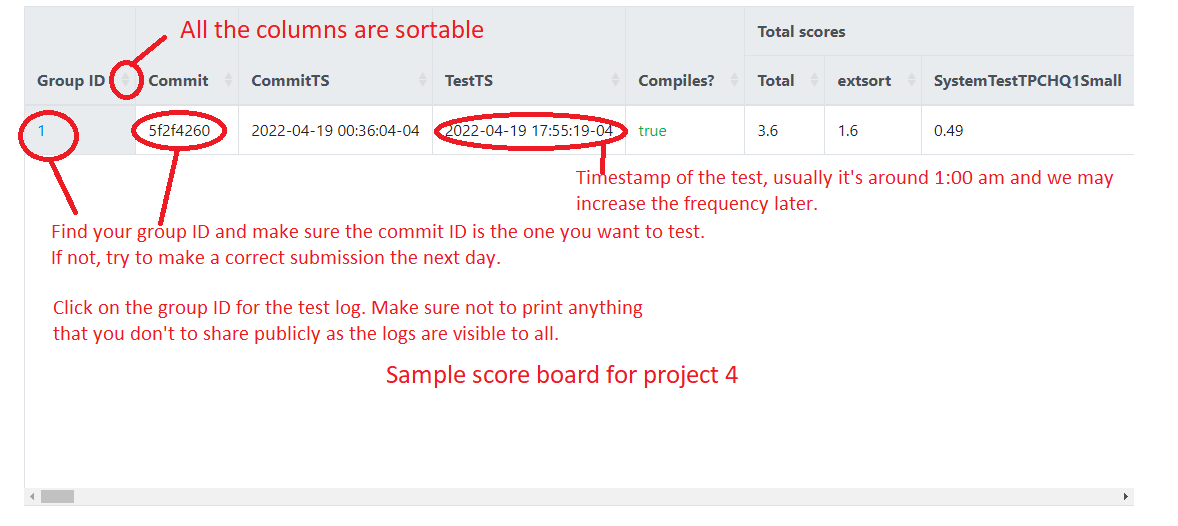
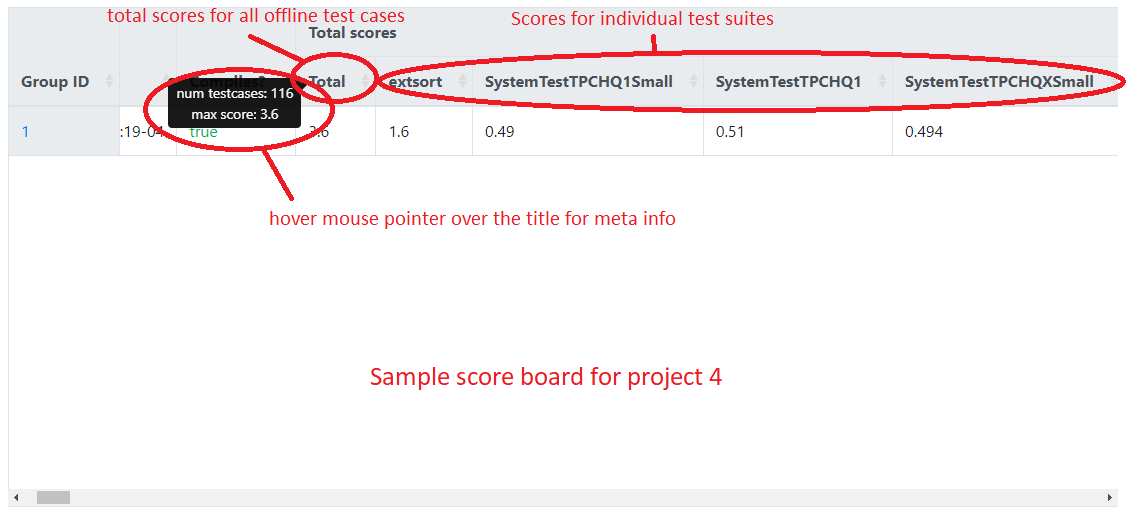
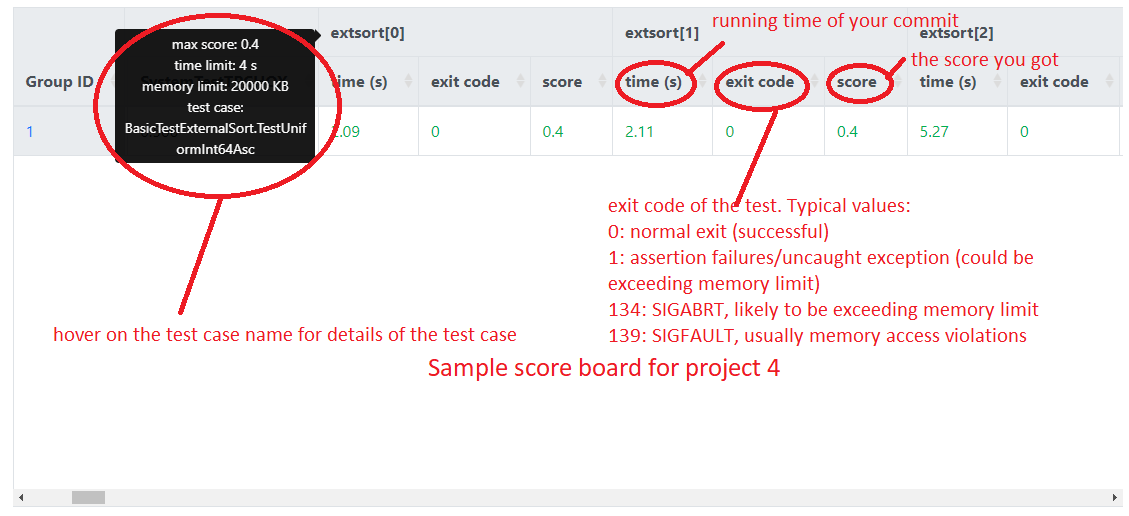
How to run large tests locally: if you run the large tests
locally with the debug build, they will likely to time out because
no compiler optimization is enable in debug build. To enable
compiler optimization locally, you'll need to create a new build
directory as follows (assuming the new folder is called
build.release):
# in repository root
cmake -Bbuild.release -DCMAKE_BUILD_TYPE=Release .
cd build.release
make
How to run large tests locally:
We provide a few scripts for running external sorting basic tests with
the default timeout and memory limits set to a higher number. To run the
tests with the default, run either ctest -R test_name
or:
cd build.release
./tests/extsort/BasicTestExternalSort.TestXXX.sh # replace XXX with the test namesHow to specify memory limits and/or timeouts: While you won't be able to change the memory limits or timeouts we set in the offline tests, but you may need to change these values for your local environment to pass the tests locally. If you need to specify a different memory limit and/or timeouts locally during debugging, specify the MEMLIMIT variable (in KB) and/or the TIMEOUT variable (in seconds) before running the test scripts:
cd build.release
# set the memory limit to 50000KB and timeout to 100 seconds in the test
MEMLIMIT=50000 TIMEOUT=100 ./tests/extsort/BasicTestExternalSort.TestXXX.sh # replace XXX with the test names
How to thoroughly test your implementation using TPCHTest
classes: As you might have noticed, there are two new
test files tests/execution/TPCHTest.h and
tests/execution/TPCHTest.cpp. These are the test
fixtures we will use to run queries over TPC-H data in the
system tests in project 4 and in the bonus tests in project 5.
After you finish all the basic tests and want to thoroughly test
your implementation for passing the hidden system tests, you can
use them to write your own TPC-H queries over
the preloaded TPC-H data
(download here, and extract all in
data/ directory).
(IMPORTANT!) Before extracting the preloaded data, make sure add the
followling lines to .gitignore in your repository
to avoid committing these large files to Github.
/data/tpch_s1.tar.xz
/data/tpch_s1
/data/tpch_s01.tar.xz
/data/tpch_s01Upcoming: we will post the instructions of how to write your own query plans and how to run the tests when we release project 5. We will also include a few sample query plans for your reference.